Scalable Private Set Intersection Based on OT Extension
基于 OT 扩展的可扩展隐私集合求交集
隐私集合求交集(PSI)允许双方计算他们的集的交集,而不透露不在交集中的项目的任何信息。这是研究得最好的安全计算应用之一,许多 PSI 协议已经被提出。然而,现有的 PSI 协议的多样性使得我们很难确定在各自场景中表现最好的解决方案,特别是由于它们没有在相同的环境中进行比较。此外,现有的 PSI 协议比不安全的朴素散列解决方案慢几个数量级,而这是在实践中使用的。
在这篇文章中,我们回顾了在 PSI 协议方面取得的进展,并对各种安全模型中的现有协议进行了概述。然后,我们关注对半诚实对手安全的 PSI 协议,并利用不经意传输(OT)扩展的最新效率改进,对以前的 PSI 协议提出重大优化,并提出一种运行时间优于现有协议的新 PSI 协议。我们通过在同一平台上实现所有协议,从理论上和实验上比较了协议的性能,对在特定环境下使用哪种协议提出了建议,并通过与目前采用的不安全的朴素散列协议进行比较,评估了 PSI 协议的进展。我们通过处理两个各有 10 亿元素的集合来证明我们新的 PSI 协议的可行性。
1 介绍
隐私集合求交集(PSI)允许分别持有集合
PSI 是一个非常活跃的研究领域,已经有很多关于 PSI 协议的建议。大量建议的协议使得进行全面的交叉评价变得非同小可。更加复杂的是,许多协议设计没有被实施和评估,在不同的假设和观察下被分析,并且经常在整体运行时间上被优化,而忽略了其他相关因素,如通信。此外,即使已经引入了几个 PSI 协议,需要计算隐私敏感列表的交集的实际应用往往使用不安全的解决方案。安全解决方案接受度低的原因是,除其他外,现有方案的效率低下,其开销比不安全的解决方案多出两个数量级。
在这篇文章中,我们概述了现有的高效 PSI 协议,优化了现有的 PSI 协议,并描述了一种基于高效不经意传输(OT)扩展的新 PSI 协议。我们在同一平台上比较了所有协议的理论和经验性能,并评估了它们与实践中使用的不安全的基于哈希的解决方案相比的成本。我们表明,与实践中使用的解决方案相比,我们的新 PSI 协议实现了合理的开销。
1.1 应用
我们工作的动力来自于几个需要 PSI 功能的实际应用。在下文中,我们列出了其中的三个应用:
衡量广告转化率:衡量广告转化率是通过比较看过广告的人和完成交易的人的名单来进行的。这些名单分别由广告商(例如谷歌或 Facebook)和商家持有。通常有可能在两端识别用户,使用诸如信用卡号码、电子邮件地址之类的标识。一个忽视隐私的简单解决方案是,一方向另一方披露其客户名单,然后由后者计算出必要的统计数据。另一个选择是在双方之间运行一个 PSI 协议。(该协议可能应该是 PSI 的一个变体,例如,计算看过广告的客户的总收入)。这种协议可以从基本的 PSI 协议中衍生出来)。事实上,Facebook 正在与 Datalogix、Epsilon 和 Acxiom 等公司运行这种类型的服务,这些公司拥有美国大部分会员卡持有人的交易记录。我们的结果表明,即使对于大型数据集,也可以使用安全协议进行计算。
安全事件信息共享:安全事件处理人员可以从信息共享中获益,因为这为他们在事件发生期间提供了一个全局视图。然而,事件数据往往是敏感的,而且可能是令人尴尬的。共享的信息可能会泄露提供信息的公司或其客户的业务信息。因此,信息的共享通常是相当稀少的,并使用法律协议进行保护。自动化的大规模共享将提高安全性,事实上,已经有了这方面的工作,如 IETF 管理事件轻量级交换(MILE)工作。许多应用于共享数据的计算都是计算交叉点及其变体。应用 PSI 来执行这些计算可以简化信息共享的法律问题。高效的 PSI 协议将使其能够经常和大规模地运行。
隐私的联系人发现:当一个新的用户注册到一个服务时,识别当前的注册用户也是新用户的联系人往往是很重要的。这个操作可以通过简单地将用户的联系人列表透露给服务来完成,但也可以通过在用户的联系人列表和服务的注册用户之间运行 PSI 协议来以保护隐私的方式完成。后一种方法被 Signal 和 Secret 应用程序使用,但由于性能原因,它们使用了不安全的朴素散列 PSI 协议。由于可扩展性的原因,Signal 计划使用基于英特尔 SGX 的解决方案,如 Tamrakar 等人(2017)提出的。
在这些情况下,每个用户有少量的记录
1.2 PSI 协议的分类
安全地将两个集合相交而不泄露任何信息(除了相交的结果)是安全计算中最突出的问题之一。已经提出了几种实现 PSI 功能的技术,如高效但不安全的朴素散列解决方案,需要半信任的第三方的协议,或两方 PSI 协议。最早提出的两方 PSI 协议是基于公钥密码学的特殊用途解决方案。后来,人们提出了使用基于电路的安全计算通用技术的解决方案,这些技术大多基于对称密码学。最近的发展是仅基于 OT 的 PSI 协议,并结合了对称加密基元的效率和特殊目的优化。PSI 协议已经在智能手机上实现和评估(Huang 等人,2011;Asokanetal.2013;Kissetal.2017)。
一个朴素的解决方案:当遇到 PSI 问题时,大多数新手都会想出一个解决方案,即双方都对他们的输入应用一个加密哈希函数,并比较这些哈希值。虽然这个协议非常有效,但如果输入域很小或熵很低,它就不安全,因为一方可以很容易地进行蛮力攻击,将哈希函数应用于可能出现在输入集中的所有项目,并将结果与收到的哈希值进行比较。(当 PSI 的输入具有高熵时,可以使用比较输入的哈希值的协议(Nagy 等人,2013))。
基于第三方的 PSI:已经提出了几个利用额外方的 PSI 协议,例如,Baldwin 和 Gramlich(1985)。在 Hazay 和 Lindell(2008)中,一个可信的硬件令牌被用来评估一个不经意伪随机函数(OPRF)。在 Fischlin 等人(2011)中,这种方法被扩展到多个不可信的硬件令牌。Kamara 等人(2014)提出了几个高效的 PSI 服务器辅助协议,这些协议使用一个不持有输入、不接收输出的第三方,并假定其不与任何一方合作,并进行了基准测试。外包 PSI 协议,如 Abadi 等人(2015,2017)和 Oksuz 等人(2017),允许重复使用外包给云的加密数据集,但在单次运行中的效率低于 Kamara 等人(2014)。
基于公钥的 PSI:Meadows(1986)提出了一个基于 Diffie-Hellman(DH)密钥协议的 PSI 协议(Shamir(1980)和 Huberman 等人(1999)提出了相关想法)。他们的协议是基于 DH 函数的换元特性,并被用于私人偏好匹配,这使得双方可以验证他们的偏好是否在某种程度上匹配。
Freedman 等人(2004)在标准模型(而不是在基于 DH 的协议中假设的随机预言机模型(ROM))中引入了对半诚实的和恶意的对手安全的 PSI 协议。该协议基于多项式插值,并在 Freedman 等人(2016)中进行了扩展,提出了对恶意对手具有基于模拟安全性的协议,并评估了所提散列方案的实际效率。我们在第 3 节讨论所提出的散列方案。Freedman 等人(2005)提出了一种类似的方法,使用 OPRF 来执行 PSI。Kissner 和 Song (2005) 提出了一个使用多项式插值和微分来寻找多集之间的交叉点的协议。
Cristofaro 和 Tsudik (2010) 提出了另一个 PSI 协议,该协议使用公钥加密技术(更具体地说,盲化 RSA 操作),并以元素的数量进行线性扩展。在 Debnath 和 Dutta(2015)中,介绍了一个基于布隆过滤器的 PSI 协议系列,实现了 PSI、PSI 卡度和认证的 PSI 功能。这些协议也使用公钥操作,与元素的数量成线性关系。
基于电路的 PSI:通用的安全计算协议在过去十年中得到了很大的效率改进。它们允许对任意函数进行安全评估,表示为算术或布尔电路。Huang 等人(2012)提出了几个用于 PSI 的布尔电路,并使用姚氏混淆电路进行了评估。作者表明,他们的 Java 实现随着安全参数的增加而扩展得非常好,并且在更大的安全参数下优于 Cristofaro 和 Tsudik(2010)的盲化 RSA 协议。我们在第 4 节中对基于电路的 PSI 进行了思考并提出了新的优化方案。
基于 OT 的 PSI:Dong 等人(2013)给出了一个基于 OT 扩展的布隆过滤器的 PSI 协议,实现了对半诚实和恶意对手的安全性,Pinkas 等人(2014)对半诚实对手进行了优化。最近在 Lambæk(2016)和 Rindal 和 Rosulek(2017a)中,表明基于布隆过滤器的协议对于恶意对手来说是不安全的。Rindal 和 Rosulek(2017a)的作者展示了如何修复基于布隆过滤器的恶意安全协议,并给出了第一个恶意安全 PSI 协议的实现,该协议在 200 秒内计算出两个各有一百万个元素的集合的交集。
在 Rindal 和 Rosulek(2016)中,我们 Pinkas 等人(2014)的基于 OT 的 PSI 协议被扩展到针对弱恶意对手的安全性,并被用作批量双执行姚氏混淆电路协议的构建块。在 Lambæk(2016)中,我们 Pinkas 等人(2015)的基于 OT 的 PSI 协议对半诚实的

表 1. 在不同的
1.3 我们的贡献
我们调查了现有的针对半诚实对手的安全 PSI 协议和带有可信第三方的解决方案。然后,我们详细描述了半诚实安全的 PSI 协议,并利用仔细分析的 OT 扩展的特点改进了一些协议的性能。我们介绍了一个新的基于 OT 的 PSI 协议,对最有前途的半诚实安全 PSI 协议进行了详细的实验比较,并评估了它们与目前在现实世界应用中使用的不安全的朴素散列协议相比的开销。我们的贡献如下:
哈希的具体参数估计:Freedman 等人 (2004) 在 PSI 的背景下建议使用散列到桶的方法来减少配对比较的开销。然而,他们对相关参数的分析只是渐进式的。在第 3 节中,我们对 Freedman 等人(2004)提出的散列到桶的技术进行了经验分析,并确定了这些方案的具体参数。此外,在第 3.3 节中,我们利用 Arbitman 等人(2010)的基于排列组合的散列技术来减少存储在桶中的表示的比特长度。这提高了 PSI 协议的性能,这些协议需要的开销与元素的比特长度成线性关系,例如第 4.2 节和第 5 节的协议。
对现有协议的优化:我们利用最近对 OT 扩展的优化改进了电路协议(Asharov 等人,2013)。特别是,在第 4 节中,我们评估了 Huang 等人(2012)对 GMW 协议的安全评估的基于电路的解决方案,并利用随机 OT 的特点(参见第 2.2 节)来优化多路复用器门的性能(该门构成了大约三分之二的电路)。此外,在第 4.2 节中,我们概述了如何使用基于排列组合的散列技术来进一步提高基于电路的 PSI 的性能。
一种新的基于 OT 的 PSI 协议:我们提出了一个新的基于 OT 的 PSI 协议(第 5 节),并直接受益于高效 OT 扩展的改进(Kolesnikov 和 Kumaresan 2013; Asharov 等人 2013)。我们的 PSI 协议使用一个高效的 OPRF,它是基于 Kolesnikov 和 Kumaresan(2013)的
PSI 协议的详细比较:我们使用最先进的加密技术实现最有前途的 PSI 协议,并在一个平台上比较它们的性能。我们的实现可以在 http://encrypto.de/code/JournalPSI,作为开放源代码。据我们所知,这是第一次进行如此广泛的比较,因为以前的比较要么是理论上的,要么是比较不同平台或编程语言上的实现,要么是使用没有最先进优化的实现。我们的实现和实验将在第 6 节详细描述。某些实验结果是出乎意料的。我们在表 2 中对我们的结果做了部分总结。接下来我们简要介绍一下我们最突出的发现。
- 基于 DH 的协议(Meadows 1986)是第一个 PSI 协议,实际上是最有效的通信方式(当使用椭圆曲线加密实现时)。因此,它适用于有强大计算能力但连接能力有限的远方当事人的情况。
- 基于电路的通用协议(Huang 等人,2012)的效率低于较新的基于 OT 的构造,但它们更灵活,可以很容易地适应计算集合相交功能的变体(例如,计算相交的大小是否超过一些阈值)。我们的实验也支持 Huang 等人(2012)的说法,即基于电路的 PSI 协议比 Cristofaro 和 Tsudik(2010)的基于盲化 RSA 的 PSI 协议在较大的安全参数和足够的带宽下更快。
- 与不安全的朴素散列解决方案相比,以前的 PSI 协议在运行时间或通信方面的效率至少低两个数量级。我们的基于 OT 的 PSI 协议在运行时间和通信方面都将这种开销降低到只有一个数量级。
- 当与大小不等的集合相交时(
),大多数协议之间的运行时间差异仍然与集合大小相等( )的运行时间差异相似。唯一的例外是新增加的基于电路的 OPRF 协议(第 4.3 节),它在不等的集合大小上实现了与朴素散列和服务器辅助解决方案类似的性能。
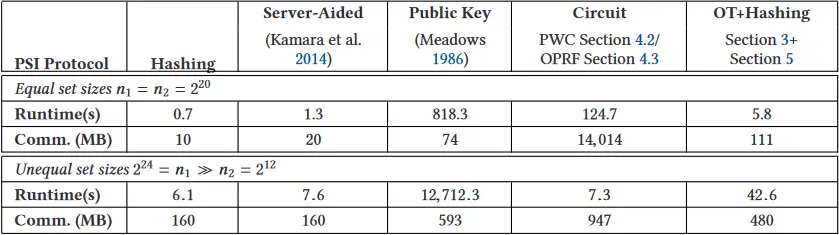
表 2. 单线程在千兆位局域网上对具有
1.4 对会议版本的补充
本文是会议论文(Pinkas 等人 2014)和 Pinkas 等人(2015)的显著扩展和改进版本。与这些论文相比,我们增加了以下贡献:
更广泛的范围:我们扩大了工作范围,在第 4.3 节中对 Pinkas 等人(2009)的基于电路的 OPRF 协议进行了描述和基准测试。
扩展的哈希参数分析:我们为使用成对比较的方案扩展了散列参数分析。在我们以前的工作中,我们只对一个特定的参数集的散列失败进行了约束,该参数集是为一个用例定制的。然而,PSI 协议表现良好的散列参数会随着设置的不同而改变(不平等的集合大小,不同的网络,等等)。我们展示了不同参数之间的权衡,从而产生了一大批在不同设置下表现良好的参数。
优化:在以前的工作中,我们基于 OT 的 PSI 协议在输入的比特长度上进行了线性扩展,这降低了它在任意输入数据上的性能。现在,我们在第 5 节中概述了如何通过使用底层基元的更有效实例来实现独立于比特长度的性能(参见第 2.2.3 节)。
不等值集的大小:我们将工作的重点扩展到不等值集的大小,其中
可扩展性:到目前为止,对安全的两方 PSI 协议进行评估的最大集合的大小为
2 初步了解
我们在第 2.1 节中给出了我们的符号和安全定义,在第 2.2 节中回顾了最近关于 OT 的相关工作,并在第 2.3 节中概述了如何将大的输入散列到小的域中。
2.1 符号和安全定义
我们把双方称为
对手的定义:安全计算文献考虑了两种具有不同强度的对手:半诚实的对手试图从给定的协议执行中尽可能多地了解信息,但不能偏离协议步骤。半诚实的对手模型适合于这样的场景:通过软件证明保证预定软件的执行,或者不受信任的第三方能够在协议执行后获得协议的记录,无论是通过偷窃还是通过法律强制披露。更强大的恶意对手通过能够任意地偏离协议而扩展了半诚实的对手。
大多数 PSI 的协议,以及这篇文章,都侧重于针对半诚实对手的安全解决方案。恶意设置的 PSI 协议是存在的,但它们的效率不如半诚实设置的协议(例如,见 Freedman 等人(2004),Cristofaro 等人(2010),以及 Rindal 和 Rosulek(2016,2017a,2017b))。目前,最快的恶意安全协议(Rindal 和 Rosulek 2017b)只比 Kolesnikov 等人(2016)的半诚实协议慢 3 倍。我们还注意到,用姚氏协议评估的基于电路的 PSI 协议可以通过使用具有恶意安全的 OT 扩展来有效地防止恶意客户端(例如 Asharov 等人(2015)),这增加了很少的开销:基于 OPRF 的协议直接和基于 SCS 的协议需要我们添加一个小电路,确保输入被排序。
安全定义:按照 Goldreich(2004)的定义,如果参与协议的一方所能计算的东西只能根据这一方的输入和输出来计算,那么这个协议就是安全的。也就是说,在协议中传递的实际信息除了输入和输出之外,没有提供其他的信息。这个定义是基于模拟范式而正式确定的:要求在协议执行中一方的观点(即该方在协议中发送和接收的所有消息)可以仅根据其输入和输出进行模拟。我们注意到,在半诚实对手的情况下,以及协议计算确定性功能(如交集功能)的情况下,只需模拟器输出被对手控制的一方的观点即可。关于安全的详细定义,见 Goldreich(2004)。
随机预言机模型 (ROM):和以前大多数关于高效 PSI 的工作一样,我们使用 ROM 来实现更高效的实现(Bellare and Rogaway 1993)。加密结构的安全性可以在 "标准模型" 中得到证明,在该模型中,安全性是基于经过充分研究的复杂性假设,或者在 ROM 中,它是基于将散列函数建模为随机函数(Bellare 和 Rogaway 1993)。关于 ROM 有很多批评意见,在密码学证明理论中,这种模型被认为是启发式的。然而,ROM 中的协议往往比在标准模型中证明的协议更有效。
使用 ROM 的效率提升在 PSI 的协议方面尤其如此。我们描述的唯一一个在标准模型中的半诚实协议是 Freedman 等人(2004,2016)的基于不经意多项式评估的协议,但该协议的效率低于我们介绍的其他协议。基于公钥的协议(基于 DH 和盲化 RSA)使用一个哈希函数
相关性稳健函数 (CRF):一个 CRF
不经意伪随机函数:OPRF(Freedman 等人,2005)是一个函数
2.2 不经意传输
OT 是安全计算的一个主要构建模块。当在
OT 扩展(Beaver 1996;Ishai 等人 2003)将
最近,OT 扩展协议的效率得到了广泛的关注。在 Kolesnikov 和 Kumaresan(2013)中,展示了一个高效的
2.2.1 2 选 1 的 OT 扩展
(Ishai 等人 2003)描述了一个

的输入: 对 比特字符串 , 。 的输入:选择向量 。 - 公共输入:对称安全参数
和基础 OT 的数量 。 - 预言机和加密基元:双方都可以访问一个
预言机,一个 PRG , 和一个 CRF 。 - 协议:
初始化一个随机向量 , 选择 个随机密钥对 , 其中 。 - 双方调用
预言机,在第 个 OT 中, 扮演输入为 的接收方, 扮演输入为 的发送方。 计算 , ,并将 发送给 , 对于 。令 表示一个由 生成的随机 位矩阵,其中第 列是 ,第 行是 , 对于 和 。 定义 ,注意 。 - 令
表示 位矩阵,其中第 列是 ,第 行是 ,注意 。 发送 ,对于每个 ,其中 , 计算 , 对于 。 - 输出:
没有输出; 输出 。
效率:总的来说,当使用 OT 扩展时,
2.2.2 随机 OT 扩展
为了提高特定环境下 OT 扩展协议的效率,一些工作(Nielsen 等人,2012;Asharov 等人,2013)使用了一种特殊用途的 OT 功能,称为随机 OT。在随机 OT 中,(
2.2.3 N 选 1 的 OT 扩展
在 Kolesnikov 和 Kumaresan(2013)中,引入了一个高效的

的输入: 个 位 元组字符串 , 。 的输入:选择数 , 。 - 公共输入:对称安全参数
, ,纠错码 。 - 协议:
计算 , ,并将 发送给 ,对于 和 。 注意: 表示一个随机 位矩阵,其中第 列是 ,第 行是 (对于 和 也是如此。)。 定义 ,注意 。 - 对于每个
和 , 计算并发送 。 - 输出:
没有输出; 输出 。
在这个
在文章的其余部分,为了便于表述,我们固定了一个线性 BCH 码,产生于 Morelos-Zaragoza(2006),它将多达
效率:使用 Kolesnikov 和 Kumaresan(2013)的
2.3 将输入哈希到较小的域
一些 PSI 协议的性能取决于其输入的表示长度。对于为输入表示的每一个比特运行一个 OT 的协议来说尤其如此,例如第 4.2 节和第 5 节中描述的协议。
当原始输入表示是稀疏的,我们可以首先使用哈希函数将输入项目的身份映射到具有较短表示的较小域中的身份。然后我们在该表示上运行原始协议,从而使执行效率更高。新域的大小应该足够大,以便没有两个不同的输入项目被映射到相同的值。与生日悖论有关的这种映射的理论分析表明,当使用随机哈希函数将
3 散列方案和 PSI
计算两个集合之间的明文交集通常是使用散列技术完成的。双方商定一个公开的随机散列函数,将元素映射到一个由多个桶组成的散列表。如果一个输入元素在交集中,双方都会把它映射到同一个桶。因此,双方只需要比较在同一桶中的元素,以确定相交的元素。因此,对于成对的比较,元素之间的平均比较次数可以从
以类似的方式,隐私计算值之间平等性的 PSI 协议可以使用散列技术来减少比较的数量(Freedman 等人,2004,2016)。这种隐私平等性测试协议的例子有 Freedman 等人(2004)、Huang 等人(2012)和 Carter 等人(2013),第 4.2 节的基于电路的协议或第 5 节的基于 OT 的协议。当朴素地使用散列技术时,如果 n 个项目被映射到
事实上,这种最坏情况分析是平衡安全和效率的关键。一方面,如果估计过于乐观,一方未能执行映射的概率就变得不可容忍。结果,输出可能是不准确的(因为不是所有的项目都能被映射到桶),或者一方需要请求一个新的散列函数(这个请求会泄露该方输入集的信息)。另一方面,如果分析过于悲观,所进行的比较的数量和因此而产生的协议开销会变得非常大。Freedman 等人(2004,2016)的工作为这种分析和由此产生的开销给出了渐进值。他们把为散列方案设置适当参数的任务留给了未来的工作。
在本节中,我们重新审视 Freedman 等人(2004,2016)使用的简单散列(第 3.1 节)和布谷鸟散列(第 3.2 节)方案。我们描述了如何在 PSI 的背景下使用这两种散列方案,并给出了一个具体的参数分析,以平衡安全性和效率。最后,我们展示了如何使用基于包络的映射来减少存储在桶中的表征的比特长度,这提高了一些 PSI 协议的性能(第 3.3 节)。
请注意,对于我们的散列失败分析,我们使用一个专门的散列失败参数
3.1 简单哈希
在最简单的散列方案中,散列表由
3.1.1 用于 PSI 的简单哈希
为了在 PSI 的背景下应用简单散列,双方都将他们的元素映射到
3.1.2 简单哈希参数分析
对
当

表 3. 根据公式 (3),将
当
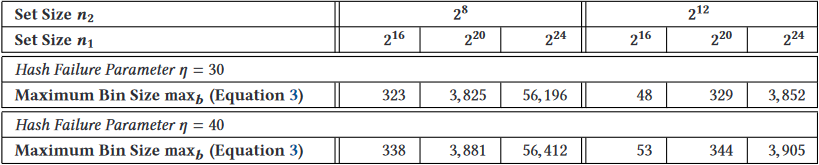
表 4. 根据公式 (3),将
3.2 布谷鸟哈希
布谷鸟散列 (Pagh and Rodler 2001) 使用
3.2.1 用于 PSI 的布谷鸟哈希
在使用布谷鸟散列法进行 PSI 时,会出现一个主要问题:每个项目都可以被映射到
3.2.2 布谷鸟哈希参数分析
布谷鸟散列有三个影响散列失败概率的参数:储藏桶大小
在下文中,我们根据经验来确定给定的存储空间大小
调整储藏桶大小
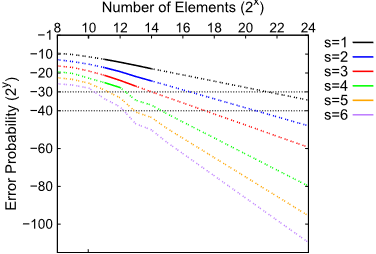
图 1. 在储藏桶大小
从结果中我们可以观察到,为了达到

表 5. 当把
调整哈希函数的数量
为了确定具体的失败概率,我们再次使用
增加哈希函数数量的后果是,使用简单哈希的一方

表 6. 根据公式 (3),当使用
调整桶的数量
为了提高不等量集合的性能,我们固定储藏桶大小
我们的实验结果在图 2 中以实线描述。从结果中,我们可以观察到,随着
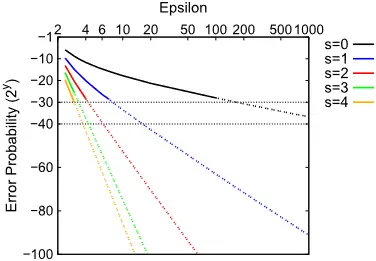
图 2. 在储藏桶大小
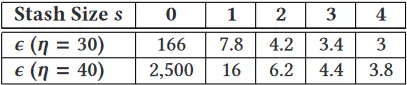
表 7. 在固定的储藏桶大小
估算结果表明,如果将储藏桶大小减少到
3.3 基于排列组合的哈希算法
第 4 节中我们基于电路的 PSI 协议和第 5 节中基于 OT 的 PSI 协议的开销取决于双方映射到桶的项目的比特长度
该结构使用类似 Feistel 的结构。让
映射函数的结构保证了如果两个项目
作为一个具体的例子,假设
4 基于电路的 PSI
与特殊目的的 PSI 协议不同,我们在本节中描述的协议是基于通用的安全计算技术,可以用于计算任意的功能。半诚实模型中两个最突出的通用安全计算协议是 Goldreich-Micali-Wigderson (GMW) 协议 (Goldreich et al.1987) 和姚的混淆电路协议 (Yao 1986)。Schneider 和 Zohner(2013)对这两个协议进行了详细的描述和比较。这两个协议都是通过将一个函数表示为布尔电路来安全地评估它,其中各方评估加密操作并为电路中的每个
使用通用协议的好处是,协议的功能可以很容易地被扩展,而不必改变协议或由此产生的协议的安全性。例如,可以直接改变 SCS 和 PWC 协议来计算交集的大小,或者一个函数来输出交集是否大于某个阈值,或者计算与交集中的项目相关的值(例如收入)的总和。使用其他 PSI 协议计算这些变体是不容易的。
4.1 用于 PSI 的排序 - 比较 - 洗牌电路 (SCS)
Huang 等人 (2012) 描述的 SCS 电路是一个大小为
对于位长为
证实了这一点。在第 6 节的实验中,我们使用 GMW 来评估 SCS 电路的深度优化变体,其中比较门有
4.2 成对比较 (PWC) 和哈希算法
执行 PSI 功能的一个更简单的电路是配对比较(PWC)电路,其中
- 双方都使用一个大小为
的表来存储他们的元素。我们的分析(第 3.2.2 节)表明,当相应地设置存储空间大小时,对于合理的输入大小( ),设置 可将错误概率降低到可以忽略不计(参见第 3.2 节)。 使用布谷鸟散列法与 个散列函数和一个储藏库将其输入元素映射到 个桶;空桶被填充了一个假元素 。 使用简单的散列法将其输入元素映射到 个桶中。桶的大小被设置为 ,这个参数的设置是为了确保没有桶溢出(参见 3.1.2 节)。每个桶中的剩余槽被填充了一个哑元素 。第 3.1.2 节中描述的分析显示了 是如何计算的,并被设置为一个小于 的值。 - 双方安全地评估一个电路,该电路将被
映射到桶的元素与被 映射到它的每个 元素进行比较。 - 最后,通过安全地评估计算该功能的电路,检查
储藏桶的每个元素是否与 的所有 输入元素相等。 - 为了减少分桶中元素的比特长度,以及电路的大小,该协议使用了第 3.3 节中描述的基于排列组合的散列。
效率:让
优点:PWC 电路比 SCS 电路有几个优点:
- 与 SCS 电路中的
门的数量相比,它是 (参见 Huang 等人(2012),并回顾 ,以及表 3 中 被证明在 和 时不大于 (而且渐进地不大于 )。与 SCS 电路中的非线性门的数量相比,PWC 电路的非线性门的数量要小 倍以上(尽管两个电路的渐进大小相同)。 - PWC 电路的主要优点是
的低 深度,这也与元素数 无关。这影响了 GMW 协议的开销,该协议需要对电路中的每一级进行一轮交互。 - PWC 电路的另一个优点是其结构简单。每个桶都要评估相同的小型比较电路。这一特性使得 SIMD(单指令多数据)评估具有很低的内存占用率,并易于并行化。
- 最后,SCS 电路的效率是为相等的集合大小量身定做的。对于不相等的集合大小
,它的电路尺寸不能很好地扩展,最多只能提高 倍。 相反,PWC 电路对于不相等的集合大小的扩展要好得多,在我们的实验中,它提高了 倍到 倍。
4.3 对 OPRF 的安全评估
Freedman 等人(2005)和 Pinkas 等人(2009)概述了另一种基于电路的 PSI 方法,并使用 OPRF(参见 2.1 节)。在这个协议中,各方使用安全计算来评估一个伪随机函数
效率:基于电路的 OPRF 构造的效率主要取决于伪随机函数
5 基于 OT 的 PSI
在本节中,我们描述了我们新的基于 OT 的 PSI 协议,其早期版本出现在 Pinkas 等人(2014,2015)中。与会议版本相比,我们改进了我们的协议,使其复杂性现在与现实集合大小的位长
散列:在我们基于 OT 的 PSI 协议的第一步中,双方已经将他们的元素映射到散列表
计算 OPRF:主要的观察结果是,我们可以使用 OT 来实例化 OPRF 功能。这一步可以使用随机 OT 来实现,因为不需要发送方明确设置传输值。此外,我们可以使用 Kolesnikov 和 Kumaresan(2013)的
计算交叉点:在
效率:主要的计算和通信开销来自于 OPRF 的评估。OPRF 的效率在很大程度上取决于基础实例化。我们使用 Kolesnikov 和 Kumaresan(2013)的
正确性:在下文中,我们将分析该方案的正确性。我们假设,在协议 3 中,
如果
如果
安全性:安全性的证明遵循半诚实对手的安全计算的常见安全定义(Goldreich 2004)。我们表明,PSI 协议中
对
6 评估
在下文中,我们将评估之前所概述的最有希望的 PSI 协议。我们首先讨论了它们的实现特点,并在理论上对它们进行了比较(第 6.1 节)。然后,我们对不同环境下的协议进行了经验性的性能比较(第 6.2 节)。在整个评估过程中,我们将 PSI 协议分为四类,取决于协议是否基于公钥操作、电路、OT 或提供有限的安全性,并将每一类的最佳结果用黑体字标出。
6.1 理论评估
在评估 PSI 协议的实际性能之前,我们讨论了协议的实现特点,如它们是否适合在有几百万元素的集合上进行大规模的 PSI(第 6.1.1 节)或方案的并行化能力(第 6.1.2 节),并给出它们的渐进计算和通信复杂性(第 6.1.3 节)。
6.1.1 适用于大规模的 PSI
尽管几乎没有讨论过,但在实施对大量数据进行操作的加密方案时,内存消耗是一个非常大的问题。因此,许多实现的 PSI 协议很快就超过了主内存,需要更多的工程努力和更仔细的实现,以便在更大的集合上实现 PSI。事实上,即使计算数十亿元素的集合的明文相交也会成为一个繁琐的问题,因为在执行过程中至少有一个集合需要完全存储。在这种情况下,人们可以将数据存储在磁盘上,这在进行任意查找时,性能会大大降低。
有限安全和基于公钥的 PSI:朴素哈希、服务器辅助和基于公钥的 PSI 方案是非常有效的内存,因为它们只在单个元素上操作,并且可以很容易地进行流水线操作,即使在标准 PC 上也可以对数百万个元素进行 PSI。
基于电路的 PSI:基于电路的 PSI 方案有很高的内存消耗。在我们的实现中,如果不再使用门,我们会评估和删除门以减少内存消耗。姚明的混淆电路比 GMW 有更高的内存消耗,因为每条线都要存储
基于 OT 的 PSI:Dong 等人(2013)和 Pinkas 等人(2014)的混淆布隆过滤器和随机混淆布隆过滤器 PSI 协议需要随机访问布隆过滤器中的位置来识别相交的元素。因此,整个布隆过滤器需要保存在内存中,或者需要外包给磁盘,但这将导致更高的运行时间。混淆布隆过滤器持有
6.1.2 计划的可并行性
我们在实证评估中进行的实验只考虑使用单线程执行。然而,如果有更多的计算资源,这些方案可以使用多线程运行,以提高其性能。然而,请注意,许多协议(即除了基于公钥的协议之外的所有协议)的瓶颈很快就从计算转移到了通信,因为使用 AES-NI 可以非常有效地评估对称加密操作。在下文中,我们将讨论这些方案的并行化能力。
有限安全和基于公钥的 PSI:由于各元素的处理是相互独立的,因此朴素哈希、服务器辅助和基于公钥的 PSI 方案很容易被并行化。所有这些方案中并行化的主要瓶颈是在每个协议结束时进行的哈希值的明文交叉。
基于电路的 PSI:基于电路的 PSI 协议根据底层安全计算协议以不同方式进行并行化。GMW 协议使用 OT 扩展来预计算乘法三元组。这一步是主要的计算工作量,可以很好地并行化。然而,GMW 的电路评估需要各方之间的顺序互动,这种互动在电路的深度上是线性的,不能被并行化。另一方面,姚的混淆电路是一个恒定的回合协议。它的并行化能力取决于基础电路结构。可以分成许多相互独立的子电路的电路,如 PWC 和 OPRF 电路,可以很容易和有效地进行并行化,而所有门都相连的电路,如 SCS 电路,需要依赖电路的方法进行并行化。
基于 OT 的 PSI:对于所有基于 OT 的 PSI 协议,它认为底层的 OT 扩展协议可以很好地并行化。可并行化的主要差异是由于用于将元素映射到相应结构中的散列方案。在 Dong 等人(2013)的基于混淆布隆过滤器的 PSI 协议中,
6.1.3 渐进式性能比较
我们在表 8 中描述了拥有大部分工作量的一方的渐进计算复杂度和 PSI 协议的总通信复杂度。计算复杂度表示为对称加密原语评估数(
我们从渐进复杂度中得到的最关键的观察是,渐进地,相同类型的方案之间的性能几乎是相等的。朴素散列和服务器辅助协议都需要对每个元素进行
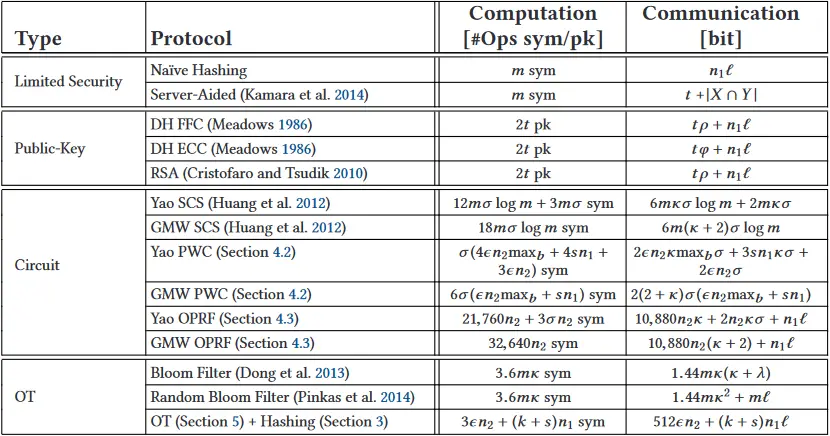
表 8. PSI 协议的渐进复杂度 (
6.2 实验评估
我们对所提出的半诚实的 PSI 协议的性能进行了实证评估和比较。根据 NIST 的建议,所有协议都以
6.2.1 测试环境
我们在一个局域网和一个广域网设置中进行了实验。局域网设置包括两台通过千兆以太网连接的 PC(英特尔 Haswell i7-4770K CPU,3.5GHz,16GB RAM)。广域网设置包括两个亚马逊 EC2 m3.medium 实例(英特尔至强 E5-2670 CPU,2.6GHz,3.75GB 内存),分别位于北弗吉尼亚(美国东海岸)和法兰克福(欧洲),平均带宽为 98MBit/s,平均往返时间为 94ms。
我们在两种情况下评估 PSI 协议的性能。在第一种情况下,
实施方案:基于盲化 RSA(Cristofaro 和 Tsudik 2010)和混淆布隆过滤器(Dong 等人,2013)协议的实现取自作者,但我们使用哈希表来计算盲化 RSA 协议中找到交集的最后一步(原始实现使用了具有二次运行时间开销的配对比较),以及 Asharov 等人(2013)对布隆过滤器协议的 OT 扩展实现。我们在 C++ ABY 框架(Demmler 等人,2015)中使用了最先进的姚氏混淆电路和 GMW 协议实现,该框架实现了点对点(Malkhi 等人,2004)、半门(Zahur 等人,2015)、自由
我们认为,我们提供了一个公平的比较,因为所有的协议都是用相同的编程语言(C/C++)实现的,在相同的硬件上运行,并使用相同的基础库进行加密操作。
对于每个协议,我们测量了从启动程序到客户端输出相交元素的时间。所有的运行时间都是 10 次执行的平均数。
6.2.2 实验比较
我们评估了 PSI 协议在局域网环境中的经验性能,并给出了协议的具体通信。虽然局域网环境不一定代表 PSI 的真实环境,但它允许我们在一个几乎理想的网络环境中对协议进行基准测试,从而关注协议的计算复杂性。我们在图 3 中给出了
类型之间的比较:从图 3 中,我们可以观察到,除了基于 OT 的 PSI 协议外,同一类型的 PSI 协议具有相似的运行时间和通信。不安全的朴素散列协议和服务器辅助的 PSI 协议在计算和通信方面比其他 PSI 协议至少要好一个数量级。基于公钥的 PSI 协议只需要很少的通信(特别是 DH-ECC 协议),但运行时间最高。基于电路的 PWC 协议比基于公钥的协议有更快的运行时间,但需要两个数量级的通信,并且不能很好地扩展到大型集合。最后,基于 OT 的 PSI 协议在性能上有所不同:Dong 等人(2013)的 GBF 协议具有与基于电路的 PWC 协议类似的运行时间和通信,而我们的基于 OT 的 PSI 协议具有比公钥和基于电路的协议更快的运行时间,与基于电路的协议相比,需要至少少一个数量级的通信。在所有的 PSI 协议中,我们新颖的基于 OT 的 PSI 协议是最快的,而且需要的通信量与基于公钥的 PSI 协议差不多。
基于有限安全的 PSI:朴素的散列协议在运行时间和通信方面优于服务器辅助协议 2 倍之多。然而,这些协议的安全保障比我们描述的其他协议要弱。
基于公钥的 PSI:对于基于公钥的 PSI 协议,我们观察到 Meadows(1986)的基于 DH 的协议在使用有限域密码学(FFC)时优于 Cristofaro 和 Tsudik(2010)的基于 RSA 协议。基于 DH 协议的椭圆曲线加密法(ECC)实例化变得更加高效,比 FFC 实例化的效率高 2 倍。基于 ECC 协议的优势在于其通信复杂度,在所有 PSI 协议中最低(参见表 10)。我们注意到,这些协议的一个主要优势是它们的简单性,这使得它们相对容易实现。
基于电路的 PSI:这里我们比较了 Huang 等人(2012)的 SCS 电路,我们的 PWC 电路(第 4.2 节)和 OPRF 电路(第 4.3 节),使用姚的混淆电路和 GMW 进行评估。结果可以总结如下。
GMW 协议比姚的混淆电路协议快 2 倍左右,这是由于平衡通信的原因。随着集合大小的增加,PWC 电路的扩展性优于 SCS 和 OPRF 电路,对于
基于 OT 的 PSI:Pinkas 等人(2014)的随机混淆布隆过滤器协议在运行时间和通信方面比 Dong 等人(2013)的优化混淆布隆过滤器变体提高了约 1.5 倍。
我们的基于 OT 的 PSI 协议在小集规模下的运行时间比基于布隆过滤器的协议都要高,因为
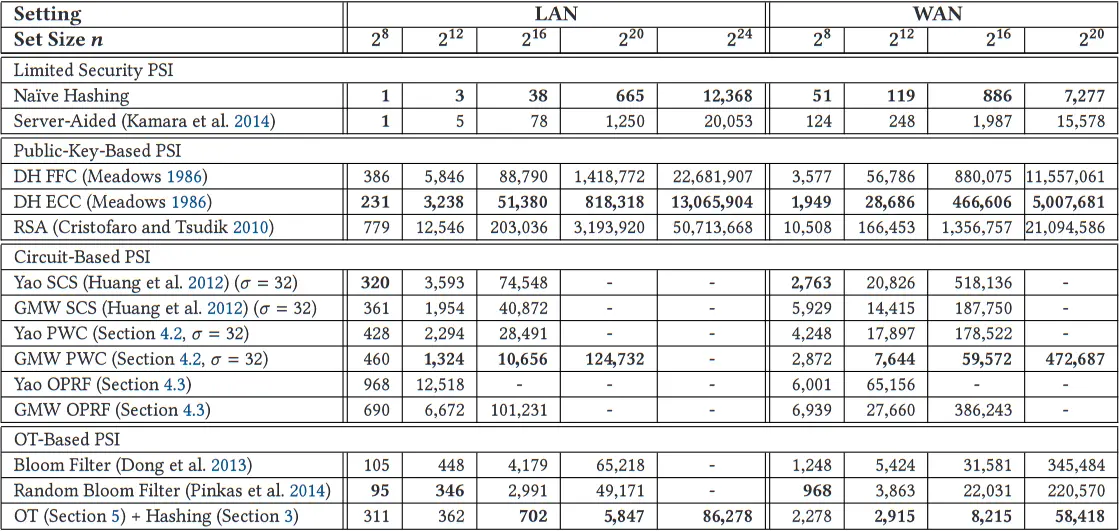
表 9. 在局域网和广域网设置中,一个线程的 PSI 协议的运行时间,单位为 ms。
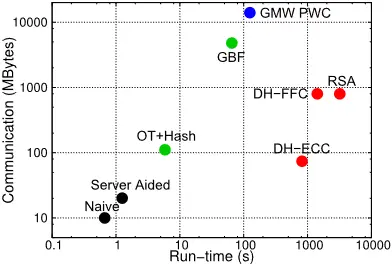
图 3.
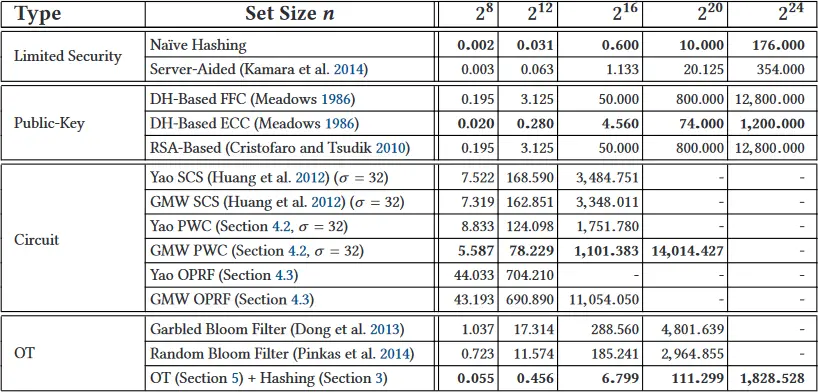
表 10. 以 MB 为单位的 PSI 协议的通信量。
6.2.3 PSI 与不平等的设置尺寸
在许多 PSI 应用中,双方的集合大小是不相等的,通常一个拥有几百个元素集合的客户与一个拥有数百万条记录的数据库的服务器进行 PSI。我们在不平等的集合大小
实验结果与相同集合大小的实验相似,但有一个明显的例外:OPRF 电路表现得非常好,实现了与服务器辅助协议相似的运行时间,甚至在
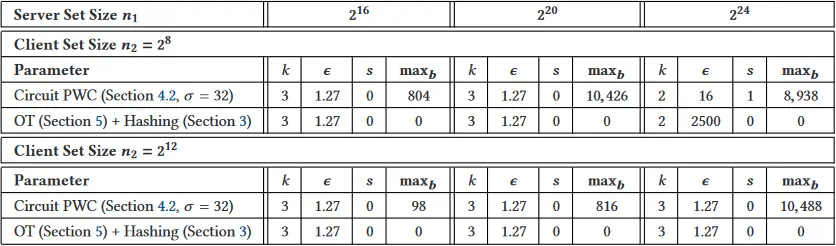
表 11. 在不等量集实验中使用的电路 PWC 和我们基于 OT 的 PSI 的参数
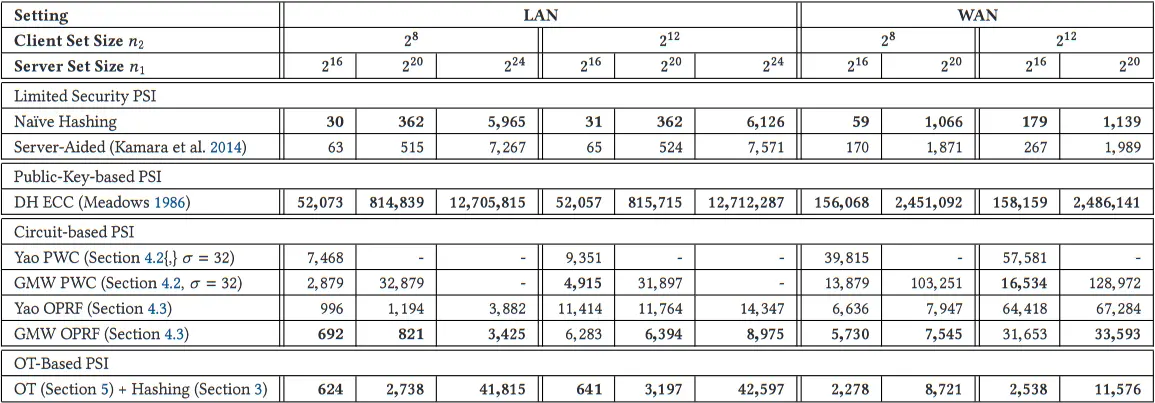
表 12. 在局域网和广域网设置中,PSI 协议的运行时间,以毫秒为单位,集合大小不等,
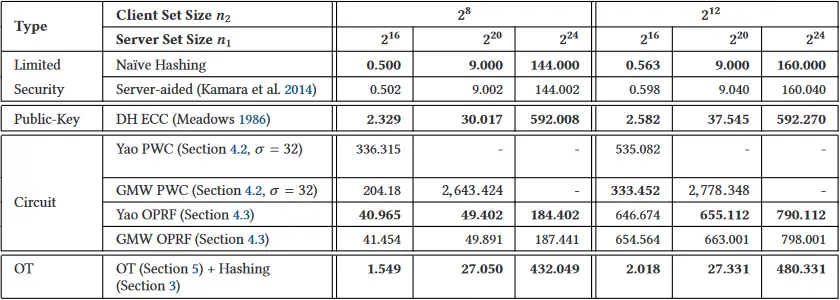
表 13. 不等集尺寸的 PSI 的通信量(MB),
6.2.4 十亿级别元素的 PSI
最后,我们通过对每个 10 亿
为了计算 20 亿元素集的交集,朴素散列需要 74 分钟,其中 19 分钟(26%)用于散列和传输数据,55 分钟(74%)用于计算明文交集。我们基于 OT 的 PSI 协议总共需要 34.2 小时,其中 30.0 小时(88%)用于简单散列(布谷鸟散列并行运行,需要 16.3 小时),3 小时(9%)用于计算 OT,1.2 小时(4%)用于计算明文相交。
参考文献
A. Abadi, S. Terzis, and C. Dong. 2015. O-PSI: Delegated private set intersection on outsourced datasets. In ICT Systems Security and Privacy Protection (SEC’15) (IFIP AICT), Vol. 455. Springer, 3–17.
A. Abadi, S. Terzis, and C. Dong. 2017. VD-PSI: Verifiable delegated private set intersection on outsourced private datasets. In Financial Cryptography and Data Security (FC’16)(LNCS), Vol. 9603. Springer, 149–168.
M. R. Albrecht, C. Rechberger, T. Schneider, T. Tiessen, and M. Zohner. 2015. Ciphers for MPC and FHE. In Advances in Cryptology—EUROCRYPT’15 (LNCS), Vol. 9056. Springer, 430–454.
Y. Arbitman, M. Naor, and G. Segev. 2010. Backyard cuckoo hashing: Constant worst-case operations with a succinct representation. In Foundations of Computer Science (FOCS’10). IEEE, 787–796.
G. Asharov, Y. Lindell, T. Schneider, and M. Zohner. 2013. More efficient oblivious transfer and extensions for faster secure computation. In Computer and Communications Security (CCS’13). ACM, 535–548.
G. Asharov, Y. Lindell, T. Schneider, and M. Zohner. 2015. More efficient oblivious transfer extensions with security for malicious adversaries. In Advances in Cryptology—EUROCRYPT’15 (LNCS), Vol. 9056. Springer, 673–701.
N. Asokan, A. Dmitrienko, M. Nagy, E. Reshetova, A.-R. Sadeghi, T. Schneider, and S. Stelle. 2013. CrowdShare: Secure mobile resource sharing. In Applied Cryptography and Network Security (ACNS’13) (LNCS), Vol. 7954. Springer, 432–440.
P. Baldi, R. Baronio, E. De Cristofaro, P. Gasti, and G. Tsudik. 2011. Countering GATTACA: Efficient and secure testing of fully-sequenced human genomes. In Computer and Communications Security (CCS’11). ACM, 691–702. R.W. Baldwin andW. C. Gramlich. 1985. Cryptographic protocol for trustable matchmaking. In Symposium on Security and Privacy (S&P’85). IEEE, 92–100.
D. Beaver. 1996. Correlated pseudorandomness and the complexity of private computations. In Symposium on Theory of Computing (STOC’96). ACM, 479–488.
M. Bellare, V. Hoang, S. Keelveedhi, and P. Rogaway. 2013. Efficient garbling from a fixed-key blockcipher. In Symposium on Security and Privacy (S&P’13). IEEE, 478–492.
M. Bellare and P. Rogaway. 1993. Random oracles are practical: A paradigm for designing efficient protocols. In Computer and Communications Security (CCS’93). ACM, 62–73.
J. Boyar and R. Peralta. 2010. A new combinational logic minimization technique with applications to cryptology. In Symposium on Experimental Algorithms (SEA’10) (LNCS), Vol. 6049. Springer, 178–189.
E. Bursztein, M. Hamburg, J. Lagarenne, and D. Boneh. 2011. OpenConflict: Preventing real timemap hacks in online games. In Symposium on Security and Privacy (S&P’11). IEEE, 506–520.
H. Carter, C. Amrutkar, I. Dacosta, and P. Traynor. 2013. For your phone only: Custom protocols for efficient secure function evaluation on mobile devices. J. Secur. Commun. Netw. (2013).
E. De Cristofaro, J. Kim, and G. Tsudik. 2010. Linear-complexity private set intersection protocols secure in malicious model. In Advances in Cryptology—ASIACRYPT’10 (LNCS), Vol. 6477. Springer, 213–231.
E. De Cristofaro and G. Tsudik. 2010. Practical private set intersection protocols with linear complexity. In Financial Cryptography and Data Security (FC’10) (LNCS), Vol. 6052. Springer, 143–159.
S. K. Debnath and R. Dutta. 2015. Secure and efficient private set intersection cardinality using bloom filter. In Information Security Conference (ISC’15) (LNCS), Vol. 9290. Springer, 209–226.
D. Demmler, T. Schneider, and M. Zohner. 2015. ABY: A framework for efficient mixed-protocol secure two-party computation. In Network and Distributed System Security (NDSS’15). The Internet Society.
G. Dessouky, F. Koushanfar, A.-R. Sadeghi, T. Schneider, S. Zeitouni, and M. Zohner. 2017. Pushing the communication barrier in secure computation using lookup tables. In Network and Distributed System Security (NDSS’17). The Internet Society.
M. Dietzfelbinger, A. Goerdt,M.Mitzenmacher, A. Montanari, R. Pagh, and M. Rink. 2010. Tight thresholds for cuckoo hashing via XORSAT. In International Colloquium on Automata, Languages and Programming (ICALP’10) (LNCS), Vol. 6198. Springer, 213–225.
C. Dong, L. Chen, and Z. Wen. 2013. When private set intersection meets big data: An efficient and scalable protocol. In Computer and Communications Security (CCS’13). ACM, 789–800.
M. Fischlin, B. Pinkas, A.-R. Sadeghi, T. Schneider, and I. Visconti. 2011. Secure set intersection with untrusted hardware tokens. In Cryptographers’ Track at the RSA Conference (CT-RSA’11) (LNCS), Vol. 6558. Springer, 1–16.
M. J. Freedman, C. Hazay, K. Nissim, and B. Pinkas. 2016. Efficient set intersectionwith simulation-based security. J. Cryptol. 29, 1 (2016), 115–155.
M. J. Freedman, Y. Ishai, B. Pinkas, and O. Reingold. 2005. Keyword search and oblivious pseudorandom functions. In Theory of Cryptography Conference (TCC’05) (LNCS), Vol. 3378. Springer, 303–324.
M. J. Freedman, K. Nissim, and B. Pinkas. 2004. Efficient private matching and set intersection. In Advances in Cryptology— EUROCRYPT’04 (LNCS), Vol. 3027. Springer, 1–19.
O. Goldreich. 2004. Foundations of Cryptography. Vol. 2: Basic Applications. Cambridge University Press, Cambridge, UK.
O. Goldreich, S. Micali, and A. Wigderson. 1987. How to play any mental game or a completeness theorem for protocols with honest majority. In Symposium on Theory of Computing (STOC’87). ACM, 218–229.
G. Gonnet. 1981. Expected length of the longest probe sequence in hash code searching. J. ACM 28, 2 (1981), 289–304.
C. Hazay and Y. Lindell. 2008. Constructions of truly practical secure protocols using standard smartcards. In Computer and Communications Security (CCS’08). ACM, 491–500.
W. Henecka and T. Schneider. 2013. Faster secure two-party computation with less memory. In Symposium on Information, Computer and Communications Security (ASIACCS’13). ACM, 437–446.
Y. Huang, P. Chapman, and D. Evans. 2011. Privacy-preserving applications on smartphones. In Hot topics in Security (HotSec’11). USENIX.
Y. Huang, D. Evans, and J. Katz. 2012. Private set intersection: Are garbled circuits better than custom protocols? In Network and Distributed System Security (NDSS’12). The Internet Society.
Y. Huang, D. Evans, J. Katz, and L. Malka. 2011. Faster secure two-party computation using garbled circuits. In USENIX Security Symposium 2011. USENIX, 539–554.
B. A. Huberman,M. Franklin, and T.Hogg. 1999. Enhancing privacy and trust in electronic communities. In ACMConference on Electronic Commerce (EC’99). ACM, 78–86.
Y. Ishai, J. Kilian, K. Nissim, and E. Petrank. 2003. Extending oblivious transfers efficiently. In Advances in Cryptology— CRYPTO’03 (LNCS), Vol. 2729. Springer, 145–161.
S. Kamara, P. Mohassel, M. Raykova, and S. Sadeghian. 2014. Scaling private set intersection to s-element sets. In Financial Cryptography and Data Security (FC’14) (LNCS), Vol. 8437. Springer, 195–215.
A. Kirsch, M. Mitzenmacher, and U. Wieder. 2009. More robust hashing: Cuckoo hashing with a stash. SIAM J. Comput. 39, 4 (2009), 1543–1561. Á. Kiss, J. Liu, T. Schneider, N. Asokan, and B. Pinkas. 2017. Private set intersection for unequal set sizes with mobile applications. Privacy Enhancing Technologies (PoPETs’17) 2017, 4 (2017), 97–117.
L. Kissner and D. Song. 2005. Privacy-preserving set operations. In Advances in Cryptology—CRYPTO’05 (LNCS), Vol. 3621. Springer, 241–257.
V. Kolesnikov and R. Kumaresan. 2013. Improved OT extension for transferring short secrets. In Advances in Cryptology— CRYPTO’13 (2) (LNCS), Vol. 8043. Springer, 54–70.
V. Kolesnikov, R. Kumaresan, M. Rosulek, and N. Trieu. 2016. Efficient batched oblivious PRF with applications to private set intersection. In Computer and Communications Security (CCS’16). ACM, 818–829.
V. Kolesnikov and T. Schneider. 2008. Improved garbled circuit: Free XOR gates and applications. In International Colloquium on Automata, Languages and Programming (ICALP’08) (LNCS), Vol. 5126. Springer, 486–498.
M. Lambæk. 2016. Breaking and Fixing Private Set Intersection Protocols. Cryptology ePrint Archive, Report 2016/665. (2016). http://ia.cr/2016/665.
D. Malkhi, N. Nisan, B. Pinkas, and Y. Sella. 2004. Fairplay—A secure two-party computation system. In USENIX Security Symposium 2004. USENIX, 287–302.
C. Meadows. 1986. A more efficient cryptographic matchmaking protocol for use in the absence of a continuously available third party. In Symposium on Security and Privacy (S&P’86). IEEE, 134–137.
G. Mezzour, A. Perrig, V. D. Gligor, and P. Papadimitratos. 2009. Privacy-preserving relationship path discovery in social networks. In Cryptology and Network Security (CANS’09) (LNCS), Vol. 5888. Springer, 189–208.
M. D. Mitzenmacher. 2001. The power of two choices in randomized load balancing. IEEE Trans. Parallel Distrib. Syst. 12, 10 (2001), 1094–1104. Robert H. Morelos-Zaragoza. 2006. The Art of Error Correcting Coding. Wiley, Hoboken (New Jersey), US. Code generation tools: http://eccpage.com.
R. Motwani and P. Raghavan. 1995. Randomized Algorithms. Cambridge University Press, New York, NY.
S. Nagaraja, P. Mittal, C.-Y.Hong, M. Caesar, and N. Borisov. 2010. BotGrep: Finding P2P bots with structured graph analysis. In USENIX Security Symposium 2010. USENIX, 95–110.
M. Nagy, E. De Cristofaro, A. Dmitrienko, N. Asokan, and A.-R. Sadeghi. 2013. Do I know you? – Efficient and privacypreserving common friend-finder protocols and applications. In Annual Computer Security Applications Conference (ACSAC’13). ACM, 159–168.
M. Naor and B. Pinkas. 2001. Efficient oblivious transfer protocols. In SIAM Symposium On Discrete Algorithms (SODA’01). Society for Industrial and Applied Mathematics (SIAM’01), 448–457.
A. Narayanan, N. Thiagarajan, M. Lakhani, M. Hamburg, and D. Boneh. 2011. Location privacy via private proximity testing. In Network and Distributed System Security (NDSS’11). The Internet Society.
J. B. Nielsen, P. S. Nordholt, C. Orlandi, and S. S. Burra. 2012. A new approach to practical active-secure two-party computation. In Advances in Cryptology – CRYPTO’12 (LNCS), Vol. 7417. Springer, 681–700. NIST. 2012. NIST Special Publication 800-57, Recommendation for Key Management Part 1: General (Rev. 3). Technical Report. National Institute of Standards and Technology (NIST), Gaithersburg (Maryland), US.
O. Oksuz, I. Leontiadis, S. Chen, A. Russell, Q. Tang, and B. Wang. 2017. SEVDSI: Secure, Efficient and Verifiable Data Set Intersection. Cryptology ePrint Archive, Report 2017/215. (2017). http://ia.cr/2017/215.
M. Orrù, E. Orsini, and P. Scholl. 2017. Actively secure 1-out-of-N OT extension with application to private set intersection. In Topics in Cryptology—CT-RSA’17 (LNCS), Vol. 10159. Springer, 381–396.
R. Pagh and F. F. Rodler. 2001. Cuckoo hashing. In European Symposium on Algorithms (ESA’01) (LNCS), Vol. 2161. Springer, 121–133.
R. Pagh and F. F. Rodler. 2004. Cuckoo hashing. J. Algorithms 51, 2 (2004), 122–144.
B. Pinkas, T. Schneider, G. Segev, and M. Zohner. 2015. Phasing: Private set intersection using permutation-based hashing. In USENIX Security Symposium 2015. USENIX, 515–530. http://eprint.iacr.org/2015/634.
B. Pinkas, T. Schneider, N. P. Smart, and S. C. Williams. 2009. Secure two-party computation is practical. In Advances in Cryptology—ASIACRYPT’09 (LNCS), Vol. 5912. Springer, 250–267.
B. Pinkas, T. Schneider, and M. Zohner. 2014. Faster private set intersection based on OT extension. In USENIX Security Symposium 2014. USENIX, 797–812. http://eprint.iacr.org/2014/447.
M. Raab and A. Steger. 1998. “Balls into bins”—A simple and tight analysis. In Randomization and Approximation Techniques in Computer Science (RANDOM’98) (LNCS), Vol. 1518. Springer, 159–170.
P. Rindal and M. Rosulek. 2016. Faster malicious 2-party secure computation with online/offline dual execution. In USENIX Security Symposium 2016. USENIX.
P. Rindal and M. Rosulek. 2017a. Improved private set intersection against malicious adversaries. In Advances in Cryptology—EUROCRYPT’17 (LNCS), Vol. 10210. Springer, 235–259.
P. Rindal and M. Rosulek. 2017b. Malicious-secure private set intersection via dual execution. Forthcoming. In Computer and Communications Security (CCS’17). ACM.
T. Schneider and M. Zohner. 2013. GMW vs. Yao? Efficient secure two-party computation with low depth circuits. In Financial Cryptography and Data Security (FC’13) (LNCS), Vol. 7859. Springer, 275–292.
R. Schürer and W. Schmid. 2006. Monte Carlo and Quasi-Monte Carlo Methods 2004. Springer, Chap. MinT: A Database for Optimal Net Parameters, 457–469.
A. Shamir. 1980. On the power of commutativity in cryptography. In International Colloquium on Automata, Languages and Programming (ICALP’80) (LNCS), Vol. 85. Springer, 582–595.
S. Tamrakar, J. Liu, A. Paverd, J.-E. Ekberg, B. Pinkas, and N. Asokan. 2017. The circle game: Scalable private membership test using trusted hardware. In Computer and Communications Security (ASIACCS’17). ACM, 31–44.
A. C. Yao. 1986. How to generate and exchange secrets. In Foundations of Computer Science (FOCS’86). IEEE, 162–167.
S. Zahur, M. Rosulek, and D. Evans. 2015. Two halves make a whole: Reducing data transfer in garbled circuits using half gates. In Advances in Cryptology—EUROCRYPT’15 (LNCS), Vol. 9057. Springer, 220–250.