Protecting accounts from credential stuffing with password breach alerting
用密码泄露警报来保护账户不被盗用
由于知识的不对称性,保护账户免受密码填充攻击的工作仍然十分繁重:攻击者可以大范围地接触到数十亿被盗的用户名和密码,而用户和身份提供者对哪些账户需要补救仍然一无所知。在本文中,我们提出了一个保护隐私的协议,根据该协议,客户可以查询一个集中的泄露库,以确定特定的用户名和密码组合是否公开泄露,但不透露查询的信息。在这里,客户端可以是一个最终用户,一个密码管理器,或一个身份提供者。为了证明我们协议的可行性,我们实现了一个云服务,该服务调解访问在泄露中发现的 40 多亿个密码,以及一个作为初始客户端的 Chrome 扩展。基于来自近 67 万名用户和 2100 万次登录的匿名遥测数据,我们发现网络上 1.5% 的登录涉及泄露的密码。通过提醒用户注意这种泄露状态,我们 26% 的警告导致用户迁移到一个新的密码,至少与原来的密码一样强大。我们的研究说明了安全的、民主化的密码泄露警告可以帮助缓解账户劫持的一个方面。
1 介绍
数据泄露所泄露的用户名和密码的广泛可用性,使犯罪分子对数十亿账户的访问变得微不足道。仅在过去的两年里,像 Antipublic(4.5 亿个密码)、Exploit.in(6 亿个密码)和 Collection 1-5(22 亿个密码)这样的泄露汇编已经稳步增长,因为它们的创建者聚集了地下论坛上分享的材料 [21, 25]。尽管这些数据是公开的,但其效力不减。以前的研究表明,6.9% 的被攻破的密码由于重复使用而仍然有效,甚至在其最初泄露的多年后仍然有效 [51]。如果没有深度防御技术将认证扩大到包括用户的位置和设备细节 [12, 17],劫持者只需要进行密码填充攻击 -- 试图用每一个被攻破的密码登录,就可以隔离易受攻击的账户。
虽然用户(或身份提供者)可以通过重设账户密码来减轻这种劫持风险,但在实践中,发现哪些账户需要关注仍然是一个关键障碍。这就催生了像 HaveIBeenPwned 和 PasswordPing 这样的泄露提醒服务,它们主动寻找被泄露的密码来通知受影响的用户 [26, 43]。目前,这些服务在用户隐私、准确性以及通过未经认证的公共渠道分享表面上的私人账户细节所涉及的风险方面做出了各种权衡。这些权衡的一个后果是,用户可能会因为误报而收到不准确的补救建议。例如,Firefox 和 LastPass 都会检查用户名的泄露状态,以鼓励用户重设密码 [13, 42],但它们缺乏关于用户的密码是否真的在某个特定网站上被泄露,或者是否曾经被重设的背景。同样有问题的是,其他方案隐含地相信泄露警报服务能够正确处理作为查询的一部分提供的明文用户名和密码。这使得泄露警报服务在被泄露(或被证明是敌对的)的情况下成为一种责任。
在本文中,我们介绍了一个新的隐私保护协议的设计、实现和部署,该协议允许客户了解他们的用户名和密码是否出现在一个泄露库中,而不透露所查询的信息。与现有的方案相比,我们的协议有两个主要优势。首先,我们的设计考虑到了对抗性客户(例如,试图从我们的服务中窃取用户名和密码的攻击者)和对抗性服务器(例如,攻击者收集发送到服务的用户名和密码)的威胁。我们使用计算成本高的散列、匿名和隐私集合求交集的组合来解决这些风险。其次,这些隐私要求使我们能够根据被泄露的密码数据库检查客户的确切用户名和密码(而不是目前只有用户名或只有密码),从而减少导致警告疲劳的假阳性。
为了证明我们协议的可行性,我们公开发布了一个 Chrome 扩展程序,当用户使用超过 40 亿个被攻破的用户名和密码之一登录网站时,会发出警告。虽然在理论上任何身份供应商或密码管理器都可以与我们的协议整合,但我们首先选择了浏览器内的警报,因为它可以扩展到长尾领域。在 2019 年 2 月 5 日至 3 月 4 日期间,来自世界各地的近 67 万名用户安装了我们的扩展。在这个测量窗口期间,我们检测到 2100 多万次登录中的 1.5% 由于依赖被泄露的密码而存在泄露,或者每两个用户就有一个警告。通过提醒用户注意这种泄露状态,我们 26% 的警告导致用户迁移到新的密码。在这些新密码中,94% 至少和原来的密码一样强大。
我们的扩展程序报告的匿名遥测数据显示,用户在超过 74.6 万个不同的域名上重复使用被泄露的密码。视频流和成人网站的劫持风险最高,其中 3.6-6.3% 的登录依赖于被泄露的密码。相反,用户似乎对密码安全建议进行了内化(或通过密码组成政策被迫这样做),特别是在金融和政府网站,只有 0.2-0.3% 的登录涉及被泄露的密码。尽管各行业之间存在差异,但我们的分析显示,密码堵塞的威胁已经延伸到互联网的长尾部分。如果没有新的认证形式,我们相信,关键是要让用户和身份提供者都能积极主动地重新确保他们的账户安全。
总之,我们将我们的主要贡献归纳如下:
- 我们开发并公开发布了一个新的协议,用于检测一个用户名和密码对是否出现在数据泄露中,而不透露被查询的信息。我们的协议改善了现有方案的隐私性,同时也降低了假阳性的风险。
- 我们概述了在实践中部署该方案的技术挑战,包括调解访问超过 40 亿个被泄露的用户名和密码所需的计算开销、延迟和成本。
- 基于现实世界的部署,我们发现整个网络上有 1.5% 的登录涉及被泄露的密码。我们提醒这只是一个下限,因为登录不是唯一的。在我们的 670,000 个用户中,大约有二分之一的用户收到了警告。
- 26% 的用户对警告的反应是重新设置他们的密码;有 94% 的新密码强度和原来一样或更高。
2 背景和要求
首先,我们建立了支撑我们的泄露警报协议的设计原则和威胁模型。我们将这些要求与 HaveIBeenPwned 和 PasswordPing 的现有解决方案以及相关的加密协议(如隐私信息检索和不经意传输)进行比较,以强调所有这些方法在隐私、开销、准确性和信任方面的权衡。
2.1 协议摘要
我们在图 1 中为我们的泄露警报服务提供了一个抽象协议。我们在整个工作中重复使用这些函数名称和术语。在这里,有一个可以访问用户名和密码元组

图 1:泄露警报服务的抽象协议。在高层次上,客户端根据对用户名和密码的一些计算产生一个请求。然后,服务器返回一个响应,允许客户端得出他们的密码是否被泄露的结论。
2.2 设计原则
民主化的访问:目前,身份提供者单独收集被泄露的密码数据,以重置其受影响的用户账户 [4, 58]。这无法扩展到所有的身份提供者,导致在各种服务和事件中的保护不完善。任何泄露警报服务都应该被所有终端用户和身份提供者所访问,因此,不需要相关各方之间的信任。这意味着我们不能依赖认证账户作为一种速率限制的形式。我们在第 2.3 节的威胁模型中更正式地定义信任。
要可操作的,而不是仅仅提醒:任何泄露警报服务都应该为用户提供准确和可操作的安全建议,例如通过密码重置来重新确保账户的安全。仅仅警告客户存在泄露的数据,如客户的电子邮件地址、电话号码或物理地址的警报,缺乏直接的恢复步骤,因此不在我们的设计范围之内。同样,仅仅警告客户密码材料被泄露(而不是所涉及的具体密码)的警报可能会导致误报。
密码是被泄露的,而不是强度弱的:只有当访问账户的所有必要信息(例如,用户名和密码)被泄露时,才应该触发警报。虽然泄露字典(通常由被泄露的密码组成)可能包括客户的弱口令,可猜测的口令,任何后续的攻击可能需要多次猜测,因此代表的威胁比完全的密码泄露小。我们假设大多数在线服务采用足够的节流措施,使这种暴力破解不切实际。相反,针对确切的用户名和密码对的攻击在野外被积极部署。事实上,Thomas 等人的研究表明,拥有被第三方泄露的非陈旧密码的用户被劫持的可能性是随机用户的十倍 [51]。我们强调被攻破的密码有助于我们优先考虑稀缺的用户注意力 [5],并避免类似于其他警告模型的潜在警告疲劳 [2]。虽然将用户迁移到更强的密码上仍然是一项重要的任务,但它不在我们设计的范围之内。
近乎实时的:客户端查询密码和了解其泄露状态之间的时间应接近实时,以便于直接与账户安全流、密码管理器或在密码输入时整合。这可能会限制任何协议所提供的隐私保护水平,因为所涉及的任何加密元组的计算开销和网络延迟。
2.3 威胁模型
民主化的访问取决于客户端和参与我们的泄露警报协议的服务器之间的相互不信任。我们在开发我们的威胁模型时,同时考虑到对抗性客户和对抗性服务器。在对抗性客户端可以访问他们自己的泄露数据集
为了解决这些威胁,我们概述了图 1 中先前概述的抽象协议的任何实施必须满足的最低安全和隐私要求。在下面讨论的安全概念中,我们使用匿名集(表示为
请求者身份的匿名性:如果对于每个密码
有界泄漏的响应:给定一个
低效的预言机:与在账户来源的登录门户上进行的猜测尝试相比,通过泄露警报服务学习
抵制拒绝服务:服务器的响应不应该比客户端的请求(包括假的请求)需要明显更多的计算。因此,攻击者应该很难找到一个序列
非威胁:有些威胁是明确地在我们的威胁模型之外的。这些威胁包括攻击者试图确认他们所接触到的泄露行为是否为警报服务所了解(例如,
2.4 现有方案的权衡
现有的泄露警报服务包括 HaveIBeenPwned 和 PasswordPing,两者都有公开记录的 API [26, 43]。每个服务的客户端包括 1Password [48] 和 LastPass [42] 密码管理器。GitHub 依靠 HaveIBeenPwned 的密码字典的本地镜像进行检测 [36]。火狐浏览器使用 HaveIBeenPwned 在当用户浏览到一个以前遭受过数据泄露的网站时,或者当用户向火狐浏览器提供他们的电子邮件地址时 [13] 警告用户。我们研究了这些协议在我们的设计原则和威胁模型方面的权衡,表 1 作为总结。
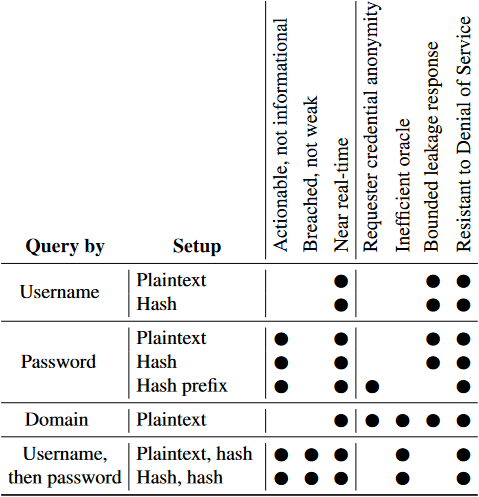
表 1:HaveIBeenPwned 和 PasswordPing 支持的协议摘要,以及根据我们的设计原则和威胁模型的权衡。
按用户名查询:HaveIBeenPwned 和 PasswordPing 都支持查询特定的明文用户名
就我们的威胁模型而言(见表 1),
重新审视我们的设计原则,我们发现仅有用户名的协议不能满足我们对可操作性而非信息性泄露警告的要求。用户可能已经改变了他们的密码,或者不再使用相关的账户。同样的,如果只对泄露的数据类型进行隔离,就不能提醒用户他们在多个网站上重复使用的密码被泄露,而这些网站中只有一个可能被泄露。
通过密码查询:PasswordPing 允许客户发送一个明文密码
正如表 1 所详述的,虽然提供
按域名查询:HaveIBeenPwned 和 PasswordPing 都提供了一个协议来确定一个域名是否是泄露的一部分。火狐浏览器目前使用 HaveIBeenPwned 来警告用户,当他们访问一个曾经遭受过泄露的域名时 [9]。这个警告指出,如果他们有一个账户,他们的数据可能不再安全。虽然这些只针对域的协议满足了我们的威胁模型中提出的每一个要求(假设不安全域的列表是本地缓存而不是查询),但它们既没有提供可操作的建议,也没有对被攻破的密码而不是弱口令的具体见解。例如,一个网站的访问者可能在密码泄露日期之后注册了一个账户。同样的,仅有域名的协议也无法捕捉到密码在被泄露和未被泄露的网站中重复使用的风险。
按用户名 - 密码查询:PasswordPing 提供了一个协议,客户端首先使用
2.5 替代加密协议
我们的威胁模型与几个经过充分研究的加密原语密切相关。这些协议提供了更严格的隐私保证,但在实践中,对于网络环境来说,计算上是非常繁重的。因此,我们的威胁模型使用了一个宽松的匿名性要求。安全的硬件飞地也能提供更严格的隐私保证,但目前的飞地已被证明容易受到旁路攻击和预测执行攻击 [53, 54]。
隐私信息检索 (PIR):Chor 等人 [6] 提出的 PIR 协议,要求用户能够从服务器上查询一个项目而不透露被查询的项目。虽然 PIR 协议对计算有限的对手 [32] 是安全的,超过了我们对请求者匿名和密码保密的要求,但他们的安全保证是片面的 -- 他们允许服务器向客户泄露关于数据库的任意信息。此外,单服务器 PIR 协议需要的通信量实际上与数据库的大小相当 [22]。多服务器 PIR 协议减少了这种开销,甚至提供了针对对抗性客户的安全保证 [19],但要求用户相信服务器之间不存在串通的风险。
不经意传输 (OT):
隐私集合求交集 (PSI):PSI 协议允许分别拥有集合
2.6 伦理
提供泄露警报服务需要访问非法获得的、然后被释放的密码。在我们的工作中,我们完全依赖现在可以公开获取的密码泄露事件,任何复杂的攻击者都可能已经获得了这些信息。因此,我们认为,让用户和身份提供者获得这些信息并不会大大增加潜在的危害,但是任何协议都应该有措施来防止滥用。由密码泄露事件泄露出来的密码在研究方面有一定的应用,包括改进密码强度表 [11,39,57] 和研究密码在野外的使用 [10]。被调查的用户也对密码泄露警报服务表达了积极的态度,特别是在重设密码的情况下 [28]。我们相信,减少账户劫持的潜力超过了整理已经公开的密码数据的任何风险。
3 泄露警报协议
我们设计的数据泄露警报协议依赖于 K - 匿名性、隐私集合求交集和计算复杂的散列的组合,以解决我们的威胁模型中列出的所有风险。在这里,我们详细介绍了我们用来实现协议的加密原语,以及客户端和服务器之间交换的数据。我们考虑了两种变体:一种是泄露一些比特的密码材料,对资源有限的攻击者是安全的(例如,攻击者无法规避 k - 匿名性和昂贵的散列);另一种是泄露零比特的密码材料,但客户必须花费两倍的时间进行散列,并收到较弱的请求者匿名性的界限。
3.1 资源受限的攻击者变体
创建数据库:在任何客户端查询之前,服务器必须构建一个安全的数据库,其中包含所有已知的被泄露的密码。我们在算法 1 中概述了这个过程。服务器首先通过去除任何大写字母和剥离与电子邮件提供者有关的信息(例如,user@gmail.com 更改为 user),将与密码相关的用户名规范化。这一步骤有助于消除重复,同时也使我们能够检测到只使用用户名而不使用电子邮件地址的网站的重复使用。在规范化之后,服务器会对规范化的用户名和密码密码计算出一个计算量很大的哈希值。我们依靠
然后,服务器通过将哈希值映射到椭圆曲线

生成请求:当生成一个请求时,客户端重复与服务器相同的散列和盲化策略。我们在算法 2 中概述了这个过程。与服务器不同的是,客户端采用自己的秘钥

生成响应:服务器根据算法 3 对请求进行响应。给定一个哈希前缀,服务器返回与该前缀相关的所有已知不安全密码
如果不提供
更正式地说,在随机预言机模型 [3] 下,以

判决:最后,客户通过完成算法 4 中详述的隐私集合求交集协议来确定他们的密码是否在泄露中泄露。这个过程完全是本地的,并且在没有独立遥测的情况下,永远不会向服务器透露匹配的判决结果。

全流程:
算法 1 创建数据库:
输入:数据集
算法:
对于数据集
将用户名
进行规范化处理,得到 。 将
与对应的密码 组合,计算哈希值 。 使用密钥
对哈希值 进行盲化处理,得到盲化哈希值 。 截取未盲化哈希值
的 字节前缀 。 利用前缀
将盲化哈希值 分区存储。
算法 2 生成请求:
输入:用户身份
算法:
- 将用户名
进行规范化处理,得到 。 - 将
与密码 组合,计算哈希值 。 - 使用密钥
对哈希值 进行盲化处理,得到盲化哈希值 。 - 截取未盲化哈希值
的 字节前缀 。 - 将生成的前缀
以及盲化哈希值 发送给服务器。
算法 3 生成响应:
输入:客户端发来的前缀
算法:
- 使用密钥
对盲化哈希值 进行盲化处理,得到 。 - 在数据库中查询前缀为
的分区,得到查询结果 ,即所有未盲化哈希前缀为 的盲化哈希值 们。 - 将
以及查询结果 返回给客户端。
算法 4 判决:
输入:服务器发来的
算法:
- 使用密钥
对行 进行去盲处理,得到 。 - 若
存在于查询结果 中,则密码泄露。
3.2 零密码泄露变体
我们之前的方法在客户端散列开销和泄露客户端密码的一些比特之间做了一个实际的权衡 (虽然仍然受到计算成本高的散列和跨越用户名和密码的匿名集的保护,但如果攻击者有关于用户名的辅助信息,这些信息就会被泄露)。 作为一个替代方案,我们概述了一个零密码泄漏的变体。在算法 2 中,客户端现在只计算用户名
3.3 扩展到元数据
我们的协议目前不包括作为元数据的已泄露密码的来源信息(例如,哪个服务被泄露)。在实践中,我们认为这是最好的策略,因为来源信息既不可信,又经常不可用。例如,像 Collection 1-5 和 Antipublic 这样的大型综合泄露包括数以亿计的密码,所有这些密码都没有归属 [21, 25]。此外,元数据扩大了作为
3.4 限制
我们的协议要求客户能够用 256MB 的内存计算昂贵的哈希值。这是阻碍攻击者的必要条件,但它也可能被证明对资源有限的设备是站不住脚的。此外,我们的方法要求客户下载一个不可忽视的数据量。就背景而言,10 亿个密码统一分为
4 实施
我们将我们的协议作为一个公开访问的 API 在谷歌云上托管。该 API 调解对超过 40 亿个独特的用户名和密码的访问,这些用户名和密码是用 Thomas 等人 [51] 以前记录的方法收集的。编码进一步将这个集合减少到 33.6 亿个密码。我们还开发了一个 Chrome 扩展程序作为概念验证的客户端,我们可以在早期的测试者中分享,以收集关于野外泄露通知的频率和影响的遥测数据。在实践中,其他处理密码的应用程序可以通过实现我们协议的一半客户端与我们的服务整合。
4.1 客户端
我们的 Chrome 扩展程序监测用户在登录页面上提交他们的用户名和密码,并对我们的 API 检测到的被泄露的密码产生浏览器警告。我们依靠 libsodium 的
检测登录事件:目前,Chrome 浏览器并没有输出用于检测登录事件的 API。相反,我们的扩展注册了一个回调函数,用于干预所有包含表单数据的 webRequests。当被触发时,该扩展依靠启发式方法来检测表单是否包含一个用户名或密码字段,如匹配字段名如 password 和 passwd。如果启发式方法未能检测到用户名和密码,就不会向我们的 API 发送任何信息。我们在 Alexa 美国排名前 50 的网站上手动测试了我们的检测:我们成功捕获了 40 个页面的登录事件,4 个失败,而剩下的 6 个没有登录表单。对于失败的页面,登录信息要么是被混淆的(例如,所有字段数据的字节包),要么是有效载荷主体的一部分,而不是表单数据。因此,当我们在第 6 节中讨论来自真实世界部署的数据时,我们要谨慎,不是每个领域都会被我们的技术所覆盖。
警告设计:我们的扩展修改了用户输入被泄露的密码的页面的 DOM,以显示类似图 2 的警告。在浏览器托盘中,用户可以到达一个显示状态警告的扩展弹出窗口 -- 类似于图 3。这为用户提供了一个查看过去警告的方法,如果他们在查看警告之前关闭了浏览器标签(或由于 DOM 刷新而覆盖了我们的修改)。此外,这也是一个安全的用户界面元素,与其他扩展和页面隔离运行。这两种风格的警告都不会透露在泄露中发现的用户名或密码的信息。这一设计决定限制了我们可以为用户提供的环境,但允许我们避免存储敏感的密码材料,这可能使持久的本地存储成为攻击的目标。
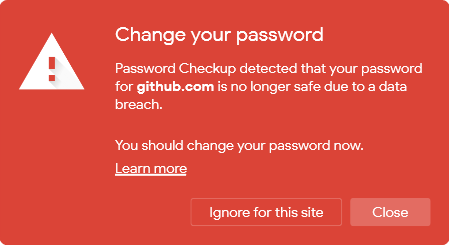
图 2:当我们检测到一个密码由于被泄露而不再安全时,我们的扩展产生的页面内警告。
在设计我们的警告时,我们遵循了关于数据泄露通知的新建议 [20],围绕数据泄露的成熟术语 [1,28],以及与网络钓鱼和不安全网络连接有关的浏览器警告的历史研究 [2,15]。特别是,我们提供了一个明确的行动 "改变你的密码",以及事件背后的危险背景。同时,我们尽量减少了不必要的或过于技术性的信息。我们还提供了一个 "了解更多" 的链接,更详细地解释了警告的根本原因和安全的最佳实践。特别是,用户应该 (1) 重新设置受影响页面的密码;(2) 在重复使用的地方重新设置密码;(3) 考虑使用密码管理器;以及 (4) 考虑采用双因素认证。在确定对话的最终设计和语言之前,我们收集了来自我们组织的 550 名早期测试者的反馈。
与其他浏览器警告(最安全的行动是关闭标签)相比,被泄露的密码要求用户遵循一系列没有指导的、主动的下一步行动。我们强调无指导性,因为每个网站都没有标准的账户安全页面来简化密码重设。虽然有行业倡议创建共同的重置路径 [41],但这些都还没有实现。因此,我们认为对警告体验的更正式的可用性研究和密码修改过程的自动化是未来的工作。我们在第 6 节中对我们的警告在成功重置密码方面的有效性进行了更深入的处理(简而言之,在我们的观察期内,四分之一的警告导致了重置)。
识别用户行为:默认情况下,我们的扩展在每次用户用被泄露的密码进行认证时,都会持续触发警告。考虑到每次 API 查询涉及的计算和网络开销,如果扩展检测到一个被泄露的密码,它会缓存
对于用户可能认为没有必要保护的低价值账户,我们提供了一个选项来忽略我们在每个域基础上的警告,如图 2 和图 3 所示。该扩展通过缓存所涉及的域的本地副本和用户忽略的密码的
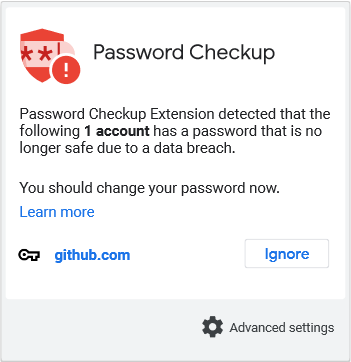
图 3:有状态的图标托盘警告信息,提醒用户哪些账户需要他们注意。这避免了页面内警告的瞬时性,我们用它来为用户提供更好的环境。
我们检测到用户重设其泄露的密码,以便向用户提供一个积极的反馈信号,即他们的账户不再有风险。我们还清除所有关于现在陈旧的密码的缓存信息。为了做到这一点,我们缓存了账户用户名的
遥测:我们利用我们的扩展来报告匿名的遥测数据,这些数据涉及到对我们的 API 的查询量,从而导致泄露警告,以及用户是否忽略我们的警告或重置他们的密码。所有这些事件都缺乏任何形式的用户标识符,排除了将事件关联起来或了解每个用户体验的可能性。每个事件还包括所涉及的登录页面的域名,我们用它来估计我们与流行网站的兼容性,并估计整个互联网上被泄露的密码的普遍性。对于与被泄露的密码有关的密码变更,我们还报告了新旧密码的强度,以了解用户是否整体上迁移到了更强的密码。我们使用 zxcvbn [57] 进行强度估计,因为它完全是客户端的,而且是开源的。这个遥测数据构成了我们分析密码泄露警告在野外的影响的基础,在第 6 节中讨论。我们在 Chrome Webstore 列表的描述中向用户预先披露了我们收集的数据。我们的所有遥测数据都由一组内部专家审查,并遵循我们组织的道德审查程序。
4.2 存储
我们将事先计算好的、经过蒙蔽和散列的密码语料库(总容量约为 110GB)划分为 216 个片区。我们将每个片断作为一个静态文件存储在谷歌云存储中。我们限制对这些文件的访问,以便只有处理请求的服务器可以从存储中获取内容。我们还在同一存储系统中存储了重新锁定客户锁定的哈希值所需的密钥材料。
4.3 服务器
我们的密码泄露协议的无状态性质使我们能够使用谷歌云功能来实现我们的服务。这种方法的主要好处是,我们可以根据传入的请求量任意扩展,同时也避免了预先申请的云实例上的休眠计算周期。这种设计还允许我们避免对跨请求的副作用进行推理。我们使用与我们的 Chrome 扩展相同的 JavaScript 椭圆曲线库来实现我们的云功能(回顾一下,散列不是服务器协议的一部分)。我们避免了应用层的拒绝服务攻击 -- 例如为服务器发送任意长度的字符串,通过阻止不遵守我们期望来自客户端的固定长度的盲文散列的畸形请求。
5 部署
我们通过 Chrome Web Store 公开了我们的扩展,并通过主要媒体渠道宣布了这一消息。在 2019 年 2 月 5 日 - 2019 年 3 月 4 日(UTC)的测量期间,总共有 66716 名用户安装了我们的扩展。
用户人口统计学:根据 Chrome 网络商店提供的综合统计数据,安装我们扩展程序的用户中有 48% 来自北美,29% 来自欧洲,17% 来自亚洲,其余 6% 来自世界各地。在操作系统方面,71% 安装扩展程序的用户使用 Windows,14% 使用 MacOS,13% 使用 ChromeOS,2% 使用 Linux。我们注意到,扩展程序在移动设备上是不可用的,因此没有出现在我们的设备分类中。
对请求的扩展:在我们的测量窗口期间,对我们的 API 的查询量从早期测试时的每 100 秒 0.11 次查询到图 4 中所示的每 100 秒 2043 次查询的峰值。图中的昼夜模式反映了用户集中在北美和欧洲的地理位置。周期性的下降反映出周末的登录活动较少。通过比较查询量和 Chrome 网络商店提供的活跃用户指标,我们估计平均每个用户每个工作日产生 3 个 API 请求(如登录),每个周末产生 1.5 个请求。至关重要的是,昼夜节律和缺乏突发行为表明在我们的测量窗口期间缺乏大规模的滥用,否则可能会污染我们在第 6 节中的分析。
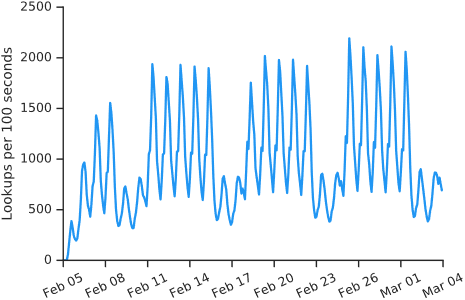
图 4:我们的扩展每 100 秒扫描的登录量。对我们的 API 的请求从早期测试的每 100 秒 0.11 次查询,到我们测量窗口结束时的每 100 秒 2192 次查询的峰值。图中的下降反映了周末期间活动的减少。
客户端的开销:我们在表 2 中列出了查询我们的 API 的客户端所产生的计算开销和网络延迟的细目。总的来说,一个中位数的查询需要 8.5 秒的时间来返回结果,在此期间,用户将继续不间断地浏览。其中大约一半的时间用于对用户的密码进行强散列,而剩余的时间则用于下载潜在的密码匹配。我们的用户名散列(用于本地缓存状态)花费的时间中位数为 100ms,是这个延迟中可忽略不计的一部分。对于 10% 的用户来说,总的查询时间超过 18 秒,其中一半是在网络延迟中度过的。虽然这种查询开销的一部分可以被优化 -- 本机代码中的密码散列平均需要 0.7 秒 -- 但减少网络延迟的唯一方法是下载更少的泄露记录,从而减少我们协议的 K - 匿名集。因此,我们目前的隐私限制对于资源有限的设备来说可能仍然是遥不可及的,至少对于接近实时的检测来说是如此。

表 2:执行 API 操作所花费的时间,包括散列和下载可能匹配的被泄露的密码。
成本建模:运行泄露检测服务的一个实际情况是成本。在我们的案例中,成本与我们提供的 K - 匿名隐私有内在的联系。在我们的存储中,每调用 1,000 次我们的 API 的成本约为 0.19 美元,目前的密码量和
6 分析
我们分析了测量窗口期间报告的匿名遥测数据,以了解整个互联网上被泄露密码的状况。我们考虑的方面包括:用户使用被泄露的密码登录的频率,重复使用最常见的网站类型,以及最终显示警告是否有助于用户解决密码被盗用的风险。我们在表 3 中提供了我们的遥测数据的高级统计摘要。我们注意到,我们的遥测数据偏向于安装我们扩展的用户,这是互联网人口的一个非随机样本。
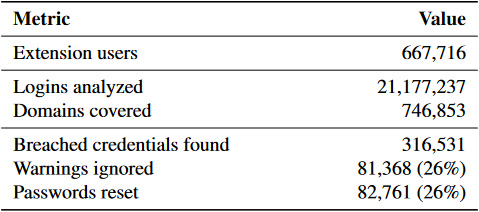
表 3:在 2019 年 2 月 5 日至 3 月 4 日我们的分析窗口期间报告的匿名遥测数据摘要。
6.1 密码填充风险和补救措施
被泄露的密码重复使用的频率:总的来说,我们的 API 处理了 21,177,237 个查询请求,其中一个查询映射到一个匿名用户进行的一次登录尝试。我们检测到 316,531 次登录涉及到被泄露的密码,占所有登录的 1.5%。我们提醒这只是一个下限,因为我们在本地缓存结果之前只对被泄露的密码产生遥测,而对未被泄露的密码的查询则在每次新的登录时产生遥测。我们的检测率低于 Thomas 等人 [51] 对 7.51 亿个谷歌账户和 19 亿个被攻破的密码报告的 6.9%。可能的原因包括采用我们扩展的用户群更有安全意识,从而避免了重复使用的行为,或者休眠账户有更高的重复使用率,由于我们在登录时进行检查,所以我们的扩展无法观察到。在我们 28 天的测量窗口中,如果我们假设登录和警告在用户中的分布是均匀的,47.3% 的用户收到了警告。我们的匿名报告排除了更详细的每个用户的统计数据。从整体上看,我们的结果显示,全球互联网用户经常访问容易受到密码堵塞的账户。
忽视被泄露的密码:用户选择忽视 81,368 个或 25.7% 的泄露警告。我们认为有三种可能的解释。用户可能正在进行明确的风险评估,认为他们账户的价值不值得采用新的密码。或者,用户可能没有完全控制账户(例如,一个共享的家庭账户)[37]。最后,由于我们的扩展并没有将重设密码的过程自动化,用户可能会因为缺乏指导而沮丧地忽略我们的警告。不管根本原因是什么,被忽视的警告会使账户容易被塞入密码。也就是说,身份提供者在这里有机会采取行动,指导用户完成密码重设过程。
对被泄露的密码进行补救:我们的警告导致用户重新设置了 82,761 个或 26.1% 的被泄露密码。重要的是,我们发现用户利用这个机会迁移到了更强大的密码。平均来说,我们发现被泄露的密码的 zxcvbn 强度为 1.6。在补救措施之后,这个分数上升到了平均 2.9。我们在图 5 中对重置前后的强度做了更详细的总结。为了说明情况,1 分表示一个 "弱密码",攻击者可以在
总的来说,94% 的密码修改导致了更强或相等的 zxcvbn 分数,而只有 6% 的修改导致了倒退到更弱的密码。我们的结果表明,我们扩展的用户了解更强的密码组成策略。同样重要的是,39% 的新密码达到了可能的最高强度分数(比原始密码的 3% 要高),这是一个潜在的迹象,表明自动编制强密码的密码管理器越来越普遍。我们的结果强调了浮现可操作的安全信息如何有助于减轻账户劫持的风险。
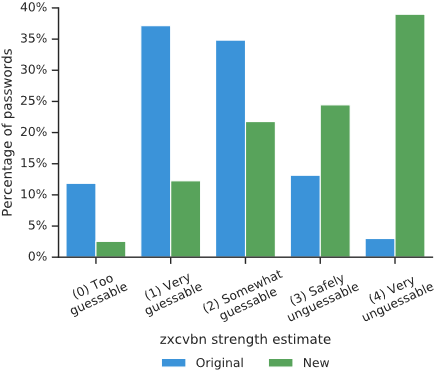
图 5:zxcvbn 密码强度的直方图,该密码被检测为被泄露,而用户在补救后采用了该密码。由于我们的警告,用户总体上向更强的密码迁移。
6.2 域名对账户安全的影响
类别:我们研究账户的感知价值是否会影响到用户对重复使用、被泄露的密码的依赖率。为了做到这一点,我们将测量期间收到超过 5,000 次登录的前 332 个域名手动标记为 13 个类别中的一个(例如金融、电子邮件和消息,以及社交网络)。我们使用了一个 "其他" 类别来涵盖不属于这个分类的领域。总的来说,这些域名的登录占了我们 API 查询的 41%。
我们在表 4 中列出了所有领域的总体警告率和忽略率的分类。被我们归类为与金融或政府有关的领域表现出最低的重复使用和被泄露的密码率(0.2-0.3%)。可能的解释包括这些领域的密码组成政策,用户坚持流行的安全建议,为他们的银行提供一个强大的密码,或者这些网站积极识别泄露行为和以前的强制密码重设。相比之下,流媒体视频平台和成人网站等娱乐网站的密码被泄露的警告率最高(3.6-6.3%)。用户可能由于认为缺乏风险而采用一次性密码,或者就流媒体网站而言,他们可能使用共享账户。令人惊讶的是,除成人网站外,用户几乎一致地忽视了我们的泄露警告。对于后者,用户忽略的警告数量几乎是我们的两倍 -- 可能是为了将域名从我们的持续警告托盘中隐藏起来(见前面的图 3)。
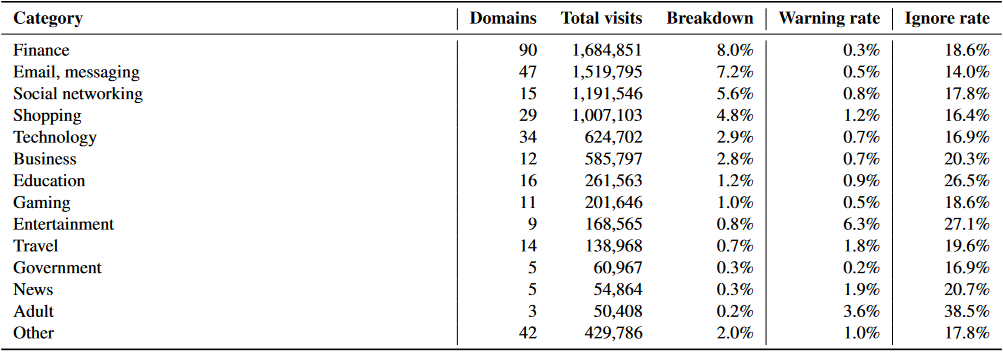
表 4:按商业领域分类,收到超过 5,000 次登录的域名中,重复使用和被泄露的密码分布情况。与娱乐和成人相关领域相比,金融和政府领域被泄露密码的使用率最低。
热门程度:我们还考虑了更受欢迎的网站是否更不容易受到密码堵塞的影响。我们在图 6 中展示了每个域名的警告频率与该域名在我们分析窗口期间的登录量的 CCDF。我们发现,只有 6% 的有 10,000 次以上登录的域名的警告率高于 3%,而少于 10,000 次登录的域名有 15%。我们认为,这种安全上的差距是由于受欢迎的域名在主动重设密码和帮助用户避免 "弱" 密码方面进行了较大的安全投资。虽然大型身份供应商同样可以利用我们的 API,但解决受密码填充影响的长尾域名可能需要依靠浏览器内的警告。
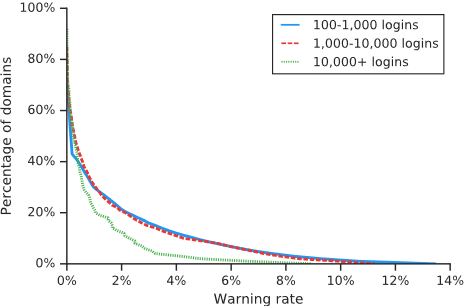
图 6:每个领域中导致警告的登录百分比的 CCDF。我们按照观察到的登录量对域名进行分组,包括 100-1,000,1,000-10,000,以及 10,000 以上。受欢迎的网站往往面临较少的密码填充的威胁,而长尾的域名仍然存在风险。
7 相关工作
帐户劫持威胁:密码填充只是账户劫持威胁的一个方面。其他风险包括大规模的网络钓鱼 [7,51],从本地机器上盗取密码或令牌 [50],甚至有针对性的攻击 [35,40]。用户已经内化了这些风险,并采用了他们与身份提供者之间共同负责的安全模式 [47]。对这些威胁最突出的解决方案包括用户采用双因素认证,或身份提供者扩大认证范围以包括其他被动因素,如用户的设备和位置 [12, 17]。我们在这项工作中提出的保护措施是对深度防御认证模型的补充,其中泄露检测代表了风险建模中的一个额外因素。
密码重复使用行为:文本密码仍然是网上认证的主流机制。考虑到人类在记忆大量独特的文本字符串方面的限制,人们采取了各种策略,包括重复使用和弱化模式,来管理他们越来越多的在线身份 [18, 23, 49, 55]。Florencio 和 Herley 发表了第一份关于密码行为的大规模研究报告,他们发现弱密码和重复使用的密码都是一个常见的缺陷 [16]。最近,Wash 等人 [56] 和 Pearman 等人 [44] 观察了数百名参与者在多个星期内的密码使用行为。他们估计,在所有输入的密码中,有 32% 的密码是完全重复使用的。Wash 等人发现,用户平均在 9 个网站上重复使用他们最常用的密码。Das 等人在直接检查泄露数据时发现,43-51% 的用户在多个网站上重复使用同一个密码 [10]。虽然自动填写密码已经变得越来越普遍 -- 参与者有 57% 的时间使用这些手段 [44]--Pearman 等人和 Wash 等人都发现密码管理器还没有被作为生成密码的工具。所有这些因素都加剧了密码填充的威胁,在这种情况下,倒置一个弱口令哈希值可以让攻击者访问多个网站。
改进泄露警报协议:在同期的工作中,Li 等人提出了一个框架,用于推理我们的协议和 HaveIBeenPwned [33] 所使用的基于密码的前缀所导致的泄漏。作者展示了一个仅有密码的前缀(或一个能够访问用户名 - 密码前缀中的明文用户名的攻击者)如何利用分区的基础密码分布来减少可能了解用户密码所需的猜测次数。为了解决这个问题,作者概述了一个零密码泄漏的变体,它依赖于私有集成员与用户名哈希前缀的分区,类似于我们自己在第 3.2 节的模型。他们的工作为零密码泄漏协议提供了进一步的动力,尽管它具有我们所概述的额外的计算复杂性。
8 总结
在本文中,我们展示了一个保护隐私的协议的可行性,该协议允许客户查询他们的登录密码是否在泄露中被泄露,而不透露所查询的信息。我们的协议依赖于计算成本高的散列、K - 匿名和隐私集合求交集的组合。我们的方法在现有协议的基础上进行了改进,考虑到了对抗性的客户端和服务器,同时也将假阳性的机会降到最低。我们设想这种服务将被终端用户、密码管理器和身份提供者使用。作为一个概念验证,我们创建了一个云服务,调解对 40 亿个被公开曝光的用户名和密码的访问。然后,我们发布了一个 Chrome 扩展程序,该程序会根据我们的服务查询登录时输入的密码。根据近 67 万名用户产生的遥测数据,我们估计整个网络上使用的 1.5% 的密码容易受到密码堵塞的影响(基于 2100 万次登录的样本)。
解决这个问题需要用户和身份提供者都采取行动。在我们的研究中,26% 的被泄露密码的警告导致用户采用了新的密码,其中 94% 的密码更强大或与原来的密码一样强大。在我们的研究中,用户的兴趣和回应率都表明,用户有兴趣保护他们的账户不被盗用。我们希望通过公开我们的协议,其他研究人员可以改进我们建立的隐私保护、计算界限和成本模型。我们的协议是民主化获取泄露警报的第一步,以减轻账户劫持的一个方面。
9 鸣谢
我们要感谢 Oxana Comanescu、Sunny Consolvo、Ali Zand 和我们的匿名审稿人,感谢他们在设计我们的泄露警报协议时提供的反馈和支持。这项工作得到了美国国家科学基金会的部分资金支持。
参考文献
Lillian Ablon, Paul Heaton, Diana Catherine Lavery, and Sasha Romanosky. Consumer attitudes toward data breach notifications and loss of personal information. In Proceedings of the Workshop on the Economics of Information Security, 2016.
Devdatta Akhawe and Adrienne Porter Felt. Alice in warningland: A large-scale field study of browser security warning effectiveness. In Proceedings of the USENIX Security Symposium, 2013.
Mihir Bellare and Phillip Rogaway. Random oracles are practical: A paradigm for designing efficient protocols. In Proceedings of the ACM Conference on Computer and Communications Security, 1993.
Borbala Benko, Elie Bursztein, Tadek Pietraszek, and Mark Risher. Cleaning up after password dumps. https: // security.googleblog.com/ 2014/ 09/ cleaning-up-afterpassword-dumps.html, 2014.
Rainer Böhme and Jens Grossklags. The security cost of cheap user interaction. In Proceedings of the New Security Paradigms Workshop, 2011.
Benny Chor, Oded Goldreich, Eyal Kushilevitz, and Madhu Sudan. Private information retrieval. In Proceedings of the Annual Symposium on Foundations of Computer Science, 1995.
Marco Cova, Christopher Kruegel, and Giovanni Vigna. There is no free phish: an analysis of "free" and live phishing kits. In Proceedings of the Workshop on Offensive Technologies, 2008.
Claude Crépeau. Equivalence between two flavours of oblivious transfers. In Conference on the Theory and Application of Cryptographic Techniques, 1987.
Luke Crouch. When does firefox alert for breached sites? https:// blog.mozilla.org/ security/ 2018/ 11/ 14/ when-does-firefox-alert-for-breached-sites/ , 2018.
Anupam Das, Joseph Bonneau, Matthew Caesar, Nikita Borisov, and XiaoFeng Wang. The tangled web of password reuse. In Proceedings of the Network and Distributed System Security Symposium, 2014.
Xavier De Carné De Carnavalet, Mohammad Mannan, et al. From very weak to very strong: Analyzing password-strength meters. In Proceedings of the Network and Distributed System Security Symposium, 2014.
Periwinkle Doerfler, Maija Marincenko, Juri Ranieri, Angelika Moscicki Yu Jiang, Damon McCoy, and Kurt Thomas. Evaluating login challenges as a defense against account takeover. In Proceedings of the Web Conference, 2019.
Peter Dolanjski. Testing firefox monitor, a new security tool. https:// blog.mozilla.org/ futurereleases/ 2018/ 06/ 25/ testing-firefox-monitor-a-new-security-tool/ , 2018.
Adam Everspaugh, Rahul Chaterjee, Samuel Scott, Ari Juels, and Thomas Ristenpart. The pythia PRF service. In Proceedings of the USENIX Security Symposium, 2015.
Adrienne Porter Felt, Alex Ainslie, Robert W Reeder, Sunny Consolvo, Somas Thyagaraja, Alan Bettes, Helen Harris, and Jeff Grimes. Improving ssl warnings: Comprehension and adherence. In Proceedings of the Conference on Human Factors in Computing Systems, 2015.
Dinei Florencio and Cormac Herley. A large scale study of web password habits. In Proceedings of the International World Wide Web Conference, 2006.
David Mandell Freeman, Sakshi Jain, Markus Dürmuth, Battista Biggio, and Giorgio Giacinto. Who are you? a statistical approach to measuring user authenticity. In Proceedings of the Symposium on Network and Distributed System Security, 2016.
Shirley Gaw and Edward W. Felten. Password management strategies for online accounts. In Proceedings of the Symposium on Usable Privacy and Security, 2006.
Yael Gertner, Yuval Ishai, Eyal Kushilevitz, and Tal Malkin. Protecting data privacy in private information retrieval schemes. Journal of Computer and System Sciences, 2000.
Maximilian Golla, Miranda Wei, Juliette Hainline, Lydia Filipe, Markus Dürmuth, Elissa Redmiles, and Blase Ur. What was that site doing with my facebook password?: Designing password-reuse notifications. In Proceedings of the ACM Conference on Computer and Communications Security, 2018.
Andy Greenberg. Hackers are passing around a megaleak of 2.2 billion records. https:// www.wired.com/ story/ collection-leak-usernames-passwords-billions/ , 2019.
Iftach Haitner, Jonathan J Hoch, and Gil Segev. A linear lower bound on the communication complexity of singleserver private information retrieval. In Proceedings of the Theory of Cryptography Conference, 2008.
Eiji Hayashi and Jason Hong. A diary study of password usage in daily life. In Proceedings of the Conference on Human Factors in Computing Systems, 2011.
Bernardo A Huberman, Matt Franklin, and Tad Hogg. Enhancing privacy and trust in electronic communities. In Proceedings of the ACM Conference on Electronic Commerce, 1999.
Troy Hunt. Password reuse, credential stuffing and another billion records in Have I been pwned. https:// www. troyhunt.com/ password-reuse-credential-stuffing-andanother- 1- billion- records- in- have- i- been- pwned/ , 2017.
Troy Hunt. Have i been pwned? https : / / haveibeenpwned.com/ , 2019.
Stanisław Jarecki and Xiaomin Liu. Fast secure computation of set intersection. In Proceedings of the International Conference on Security and Cryptography for Networks, 2010.
Sowmya Karunakaran, Kurt Thomas, Elie Bursztein, and Oxana Comanescu. Data breaches: user comprehension, expectations, and concerns with handling exposed data. In Proceedings of the Symposium on Usable Privacy and Security, 2018.
Joe Kilian. Founding crytpography on oblivious transfer. In Proceedings of the Symposium on Theory of Computing, 1988.
Hugo Krawczyk. Cryptographic extraction and key derivation: The HKDF scheme. In Proceedings of the Annual Cryptology Conference, 2010.
Brian Krebs. Sextortion scam uses recipient’s hacked passwords. https:// krebsonsecurity.com/ 2018/ 07/ sextortion-scam-uses-recipients-hacked-passwords/ , 2018.
Eyal Kushilevitz and Rafail Ostrovsky. Replication is not needed: Single database, computationally-private information retrieval. In Foundations of Computer Science, 1997. Proceedings., 38th Annual Symposium on, pages 364–373. IEEE, 1997.
Lucy Li, Bijeeta Pal, Junade Ali, Nick Sullivan, Rahul Chatterjee, and Thomas Ristenpart. Protocols for checking compromised credentials. https:// rist.tech.cornell. edu/ papers/ c3.pdf , 2019.
libsodium. The
function. https:// libsodium. gitbook . io / doc / password _ hashing / the _ i _ function, 2019. William R Marczak, John Scott-Railton, Morgan Marquis-Boire, and Vern Paxson. When governments hack opponents: a look at actors and technology. In Proceedings of the USENIX Security Symposium, 2014.
Neil Matatall. New improvements and best practices for account security and recoverability. https:// github.blog/ 2018- 07 - 31- new - improvements- and- best - practicesfor-account-security-and-recoverability/ , 2018.
Tara Matthews, Kerwell Liao, Anna Turner, Marianne Berkovich, Robert Reeder, and Sunny Consolvo. She’ll just grab any device that’s closer: A study of everyday device & account sharing in households. In Proceedings of the Conference on Human Factors in Computing Systems, 2016.
Catherine Meadows. A more efficient cryptographic matchmaking protocol for use in the absence of a continuously available third party. In Proceedings of the IEEE Symposium on Security and Privacy, 1986.
William Melicher, Blase Ur, Sean M Segreti, Saranga Komanduri, Lujo Bauer, Nicolas Christin, and Lorrie Faith Cranor. Fast, lean, and accurate: Modeling password guessability using neural networks. In Proceedings of the USENIX Security Symposium, 2016.
Ariana Mirian, Joe DeBlasio, Stefan Savage, Geoffrey M. Voelker, , and Kurt Thomas. Hack for hire: Exploring the emerging market for account hijacking. In Proceedings of The Web Conf, 2019.
Theresa O’Connor. A well-known url for changing passwords. https:// wicg.github.io/ change-passwordurl/ index.html, 2018.
Password Ping. LastPass selects PasswordPing for compromised credential screening. https : / / www. passwordping.com/ lastpass-selects-passwordping-forcompromised-credential-screening/ , 2017.
Password Ping. Block attacks from compromised credentials. https:// www.passwordping.com/ , 2019.
Sarah Pearman, Jeremy Thomas, Pardis Emani Naeini, Hana Habib, Lujo Bauer, Nicolas Christin, Lorrie Faith Cranor, Serge Egelman, and Alain Forget. Let’s go in for a closer look: Observing passwords in their natural habitat. In Proceedings of the 2017 ACM Conference on Computer and Communications Security, 2017.
Benny Pinkas, Thomas Schneider, and Michael Zohner. Faster private set intersection based on ot extension. In Proceedings of the USENIX Security Symposium, 2014.
Michael O. Rabin. How to exchange secrets by oblivious transfer. Technical report, Tech. rep. TR-81, AikenComputation Laboratory, Harvard University, Cambridge, MA, 1981.
Richard Shay, Iulia Ion, Robert W Reeder, and Sunny Consolvo. "My religious aunt asked why I was trying to sell her viagra": experiences with account hijacking. In Proceedings of ACM Conference on Human Factors in Computing Systems, 2014.
Jeff Shiner. Finding pwned passwords with 1password. https:// blog.1password.com/ finding- pwnedpasswords-with-1password/ , 2019.
Elizabeth Stobert and Robert Biddle. The password life cycle: User behaviour in managing passwords. In Proceedings of the Symposium on Usable Privacy and Security, 2014.
Brett Stone-Gross, Marco Cova, Lorenzo Cavallaro, Bob Gilbert, Martin Szydlowski, Richard Kemmerer, Christopher Kruegel, and Giovanni Vigna. Your botnet is my botnet: Analysis of a botnet takeover. In Proceedings of the ACM Conference on Computer and Communications Security, 2009.
Kurt Thomas, Frank Li, Ali Zand, Jacob Barrett, Juri Ranieri, Luca Invernizzi, Yarik Markov, Oxana Comanescu, Vijay Eranti, Angelika Moscicki, et al. Data breaches, phishing, or malware?: Understanding the risks of stolen credentials. In Proceedings of the ACM Conference on Computer and Communications Security, 2017.
International Telecommunications Union. Statistics. https:// www.itu.int/ en/ ITU-D/ Statistics/ Pages/ stat/ default.aspx, 2019.
Jo Van Bulck, Marina Minkin, Ofir Weisse, Daniel Genkin, Baris Kasikci, Frank Piessens, Mark Silberstein, Thomas F Wenisch, Yuval Yarom, and Raoul Strackx. Foreshadow: Extracting the keys to the intel SGX kingdom with transient out-of-order execution. In Proceedings of the USENIX Security Symposium, 2018.
Jo Van Bulck, Nico Weichbrodt, Rüdiger Kapitza, Frank Piessens, and Raoul Strackx. Telling your secrets without page faults: Stealthy page table-based attacks on enclaved execution. In Proceedings of the USENIX Security Symposium, 2017.
Emanuel von Zezschwitz, Alexander De Luca, and Heinrich Hussmann. Survival of the shortest: A retrospective analysis of influencing factors on password composition. In Proceedings of the International Conference on Human-Computer Interaction, 2013.
Rick Wash, Emilee Rader, Ruthie Berman, and Zac Wellmer. Understanding password choices: How frequently entered passwords are re-used across websites. In Proceedings of the Symposium on Usable Privacy and Security, 2016.
Daniel Lowe Wheeler. zxcvbn: Low-budget password strength estimation. In Proceedings of the USENIX Security Symposium, 2016.
Victoria Woollaston. Facebook and netflix reset passwords after data breaches. http:// www.wired.co.uk/ article/ facebook-netflix-password-reset, 2016.
附录 A 匿名集
在本节中,我们将更详细地描述匿名集的属性(来自第 2.3 节)。回顾一下,匿名集是用户密码的大集合,即使他们在这个集合中的成员信息被揭示,也能提供关于客户数据的合理的否认性。对匿名集的定义和争论是具有挑战性的,必须小心翼翼地进行,以避免一些琐碎的事情。为了避免构建空洞的安全性,我们要求匿名集具有以下特性:
大的边际支持:我们包含元组
更加数学化的是,给定一个大小为
用密码学上的强散列函数对用户名和密码进行散列,就可以满足这些要求。事实上,这两个集合都有可能具有和
如前文第 2.4 节所述,只对密码进行散列的方案可能仍然满足较弱的匿名性。他们隐藏了用户名,但是根据他们截断哈希值的方式,仅有密码的方案可能允许小的或大的 SuppPwd 集。因此,他们可能会满足这些要求,但至少在密码方面是弱的。此外,与我们的方案不同的是,每个密码都有一个可能是客户密码一部分的用户名,这不是真的。我们还注意到,我们的小例子,即有几个密码都绑定在同一个用户名上,违反了我们的要求,因为有
均匀性要求:这是一个更具挑战性的数学模型要求。然而,直观地讲,它指出匿名集应该以某种统一的方式划分用户名和密码的空间。换句话说,在系统参数的随机选择中,任何
在合理的假设下,我们的哈希函数是独立于典型的用户名和密码领域的,并且没有任何 "弱输入"-- 输入领域中它的行为不像是一个理想的哈希函数 -- 这一条件很容易满足。像 username,username0,username123 这样的相关密码最终都会出现在同一个匿名集合中,这是很不可能的。
附录 B 哈盲操作的安全性
在本节中,我们概述了哈希和盲操作所满足的安全属性,这是我们协议的一个重要部分。考虑一个密钥函数
Jarecki 等人 [27] 的工作表明,
假随机性 (Pseudorandomness):非正式地讲,如果一个输出在
当应用于我们的结构时,它意味着如果 b 是隐藏的,一个看到几个可能的
不经意性 (Obliviousness):如果在持有输入
当应用于我们的结构时,它指出在算法 2 中计算的组件
在这一节的最后,我们有几个说明。首先,需要注意的是,关于