An Efficient Query Scheme for Hybrid Storage Blockchains Based on Merkle Semantic Trie
基于 Merkle Semantic Trie 的混合存储区块链高效查询方案
作为一个去中心化的可信数据库,区块链在越来越多的领域找到了应用,如金融、供应链和医药追溯,大量有价值的数据被存储在区块链上。目前,主流区块链采用了链上和链下存储相结合的混合数据存储架构。对存储在这种混合系统中的海量数据进行实时分布式搜索是目前的主要需求。然而,以往的区块链系统快速检索方案只针对链上数据,没有考虑其与链下数据的相关性,因此无法满足要求。在本文中,我们通过引入一种新颖的基于 Merkle Semantic Trie 的索引技术,提出了一种高效的区块链数据查询方案,而无需修改底层数据库。利用提取的链下数据的语义信息构建共识的链上索引结构,在链上和链下数据之间建立映射,从而实现链上和链下的实时数据查询。我们的方案还提供了多种复杂的分析查询原语,以支持语义查询、范围查询,甚至是模糊查询。在三个开放数据集上的实验表明,所提出的方案具有良好的查询性能,对四种不同的搜索类型具有较短的查询延迟,并提供比现有方案更好的检索性能和验证效率。
1 介绍
随着近年来比特币 [1] 和以太坊 [2] 等加密货币系统的成功,区块链作为其核心技术引起了越来越多的关注。作为一种分布式账本技术,去中心化的防篡改区块链保证了高安全性和可靠性,以及数据的透明度 [3]。目前,它已经在供应链 [4]、金融基础设施 [5] 和数据共享 [6] 等领域找到了应用。区块链的一个常见应用场景是存储大量有价值的数据,因为它具有安全和防篡改的特点。目前主流的数据存储模式是链上和链下存储的结合 [7],其中的关键是实时数据查询。用户可以搜索感兴趣的数据,例如包含某些关键词的数据或在一定范围内的大小。因此,区块链系统需要提供实时查询功能。
不幸的是,没有任何可用的区块链系统提供这种实时查询。少数研究确实在这方面进行了探索 [8,9,10,11],但只注重查询链上存储的数据,没有考虑混合链上 / 链下架构中链上和链下数据之间的相关性。
我们发现在这种混合存储系统中,实时查询面临三个主要挑战:
现有的系统采用哈希值在链上数据和链下数据之间进行映射。这只能保证链外数据不被篡改,但无法从链上数据中获取有价值的信息,如链外数据的语义和元信息。
区块链系统在设计之初没有考虑到查询要求。链上数据以
对的形式存储在 NoSQL 数据库中,例如 levelDB。键值通常是交易数据和状态数据的唯一哈希值。数据只能用相应的哈希值进行查询,哈希值是通过哈希算法(如 和 )从数据中计算出来的随机值。用户不可能用自己选择的关键词进行查询,更不用说更复杂的操作,如范围查询和模糊查询。 区块链是一个仅有附加的数据结构 [12]。区块通过哈希指针连接,数据上下文之间没有其他对应关系。因此,数据查询和验证需要从最后一个区块一直遍历到创世区块,以保证搜索的完整性。由于在遍历过程中对磁盘的随机读取次数与块的数量成正比,随着块越来越多,时间的消耗可能是不可接受的。此外,系统中只包含头信息的轻节点需要连接到包含所有数据的全节点进行查询,由于缺少链上数据信息,轻节点很难验证全节点返回的结果。
为了解决上述三个挑战,我们提出了一个混合存储区块链系统的实时查询方案。我们采用改进的 TF-IDF 模型 [13] 来提取分布式对等网络上链外数据的语义信息。提取的语义信息和数据内容的寻址结构被存储为链上的交易。在倒置列表、哈希指针和 B + 树的基础上,构建了一个称为 Merkle Semantic Trie(MST)的索引结构,从而为语义(关键词)查询、范围查询和模糊查询提供支持,同时对查询结果进行验证。实验表明,我们的查询方案表现出良好的有效性和完整性。
我们在本文中的贡献如下:
我们提出了一种去中心化的语义提取(
)算法来提取链外数据的语义信息。提取的语义信息和数据块寻址结构被放入元数据( )中,作为链上交易存储。因此,链上数据包含相应链下数据的语义和位置信息。 我们在不改变底层数据库的情况下修改链上数据存储结构,为链上存储的每一笔交易提供可检索的键值,并以键值建立索引结构,从而实现对链上数据的高效语义、范围和模糊查询,以及与现有区块链系统的良好兼容性。
我们为索引结构提供了一个验证对象(
)。有了这个 ,只包含区块头的轻型节点能够验证从完整节点返回的查询结果。 我们采用了三个数据集来测试我们方案的性能,涵盖了加入索引结构后的空间和时间开销,以及三种数据集上四种查询类型的响应时间。与其他区块链查询方案进行了比较,表明我们的方案享有更好的响应时间,更低的查询结果验证成本和更高的有效性和完整性。
在第 2 节中,对相关工作进行了回顾。在第 3 节中,我们定义了问题和查询模式。第 4 节描述了我们的查询方案,包括索引结构和相关的查询算法。在第 5 节中,我们进行了实验,并分析了我们的方案在三个公开的数据集上的实验结果与其他方案的对比。最后,我们在第 6 节中总结了这项工作并讨论了我们未来的研究。
2 相关工作
在这一节中,我们介绍了一些关于区块链存储方案、查询相关数据结构和一些传统索引结构的相关研究。
区块链存储:区块链系统不存储底层原始数据(通常是某种格式的交易数据), 而是存储它们通过哈希算法获得的哈希值,一般不作为明文。例如,比特币使用双 sha256 哈希函数 [14],将任意长度的原始交易记录存储到区块中。大多数区块链系统的基础是键值数据库,它牺牲了读取性能以换取改进的写入性能。比特币和以太坊采用 levelDB 数据库 [2],而 Hyperledger Fabric 使用 levelDB 和 couchDB 的组合 [15]。为了提高区块链系统的可扩展性,人们提出了一些高效的混合存储方案。主要方法是将链外的大部分数据存储在分布式点对点网络中(如 Bittorrent 网络 [16] 和 Ipfs 网络 [17]),将整个数据或分区数据块的哈希值放在区块链上。链上存储的链下数据的哈希值确保了链上和链下数据的一致性,但不包含有意义的信息,如链下数据的语义。
区块链结构:区块链是一个数据结构,从一个区块链接到另一个区块。每个区块包含两个部分:区块头和区块体。而区块头包含决定区块上下文的核心数据,称为哈希指针。每个区块头都有一个 previousBlockHash,它是前一个区块的哈希值的记录。由于链式结构的特殊性,区块头的 previousBlockHash 被认为是与所有以前的区块有关,并包含时间戳信息。这种结构被认为可以保证区块链的强大数据安全性。然而,它的唯附属性也意味着对所有区块链数据的查询需要向后遍历整个链,以确保搜索结果的完整性。由于这种数据结构对只包含区块头的轻节点不友好,一些区块链系统对交易等必要数据的验证过程进行了优化。例如,基于 UTXO 模型,比特币引入了 merkle 哈希树(MHT)结构 [1],它使用层层散列来确保区块中交易的顺序不被篡改。merkle 根被存储在区块头中。光节点可以使用 merkle 根来验证区块中交易的真实性。在成立之初,比特币为轻量级节点提供了方便的认证,即简化支付验证(SPV)[1]。要验证一个区块内特定位置的交易,只需要全节点提供交易地址和相应的 Merkle 证明。事实上,我们只需要
传统的索引技术:全文索引 [18] 是搜索非结构化海量数据的关键技术,它也是谷歌和必应等搜索引擎的核心技术 [19]。与结构化数据库系统不同,存储在区块链中的海量数据没有固定的结构,所以数据库中常用的哈希索引 [20] 和 B + 树索引 [21] 并不能直接适用于区块链系统。大多数用于非结构化大数据的全文索引技术都是基于倒置索引的 [22]。倒置索引技术是对数据信息的逆向操作,采用 "关键词 - 文档" 映射来支持源数据的关键词查询,是现代信息查询最有效的索引结构。我们在混合存储区块链的方案中采用了倒置索引来构建索引结构,这在第 4.1 节中有所描述。
3 问题的定义和前提条件
我们在本文中提出了一个基于混合存储区块链的索引的分布式查询方案。该系统的架构如图 1 所示。在我们的系统中,有三种类型的节点:全节点(会计节点),光节点,和存储节点。存储节点也可以在系统中充当会计节点。轻节点可以只存储区块链的所有头信息。一个存储节点需要成为一个完整的节点来参与共识过程。我们的索引结构的查询功能可以实现快速检索,其中轻节点只需要使用他们的区块头对全节点提供的搜索结果进行简化检索验证(SRV),以验证其正确性和完整性。
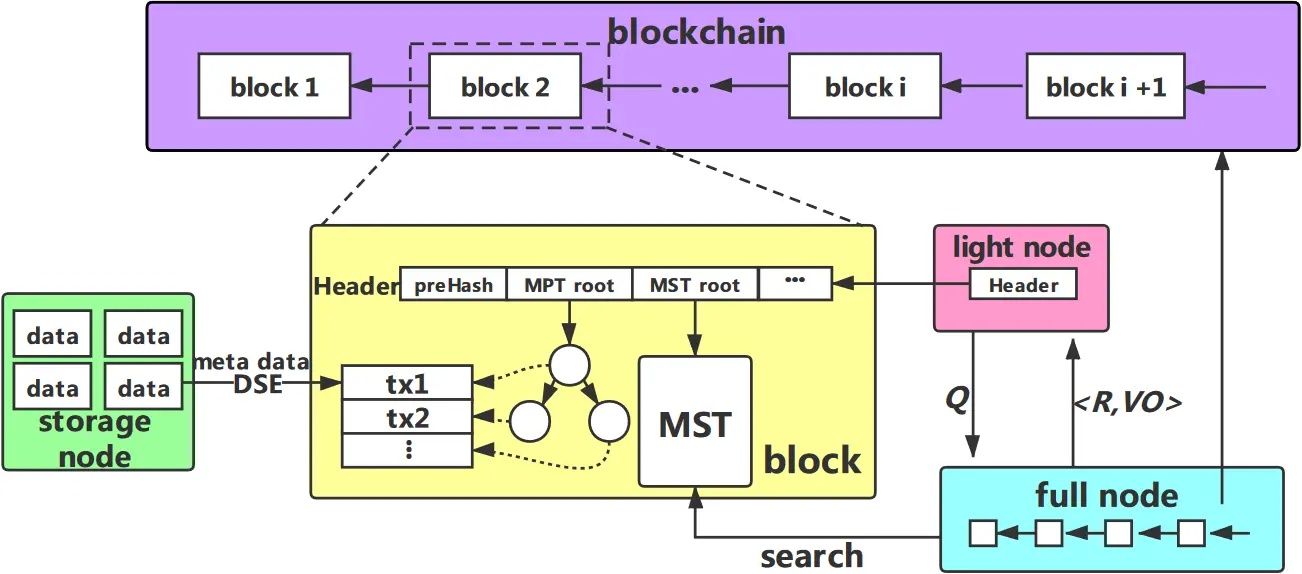
3.1 查询模型
多关键词查询是搜索引擎的一个常见功能,但现有的区块链系统并不支持这一功能。正是我们的链上索引结构使区块链上的多关键词查询成为可能。多关键词查询中典型的关键词组合是
3.2 交易结构
交易是我们将链下数据映射到链上数据的最重要方式。在区块链系统中,经过处理的交易数据以
3.3 性能和安全
由于区块链系统的去中心化特性,没有一个可信的节点负责整个系统的统一管理,所以查询的完整性和正确性是我们方案的主要关注点。恶意矿工可能会恶意节制链上的索引,而执行查询的完整节点也可能向光节点返回不完整或误导性的结果。我们系统的优越性主要在于其查询性能,体现在以下几个方面。
- 响应时间:对于各种查询,系统的时间消耗是否可以接受;
- 正确性:是否返回预期的查询结果;
- 完备性:是否返回所有的查询结果。
4 方法
我们主要关注的是实时关键词查询。如前所述,关键词查询主要通过全文索引来实现。对海量数据进行索引的成本非常高。因此,我们首先提取链外数据的语义信息,根据关键词的重要性选择少量极具代表性的关键词,最后对这些关键词构建一个倒置的索引,并维护一个名为 Merkle semantic trie(MST)的全局搜索树结构。我们设计了一个改进版的 Aho-Corasick 自动机 [23],用于查询过程中的关键词匹配,实现了模糊查询与精确匹配。我们还在 MST 中引入了 B + 树功能,以支持范围查询。
详细介绍了链外信息提取、链上索引、查询和验证,随后对索引结构进行了优化,进一步支持范围查询。
4.1 链外信息提取
首先,我们提取链下数据的语义信息,以建立链下数据和链上数据之间的映射。我们提出了一个改进的 TF-IDF 模型 [13],我们称之为分散化语义提取(DSE)。DSE 通过引入分散的词频、语篇和位置因素来提高语义特征提取的精度,以解决传统关键词提取算法中的语义理解不足问题。在此基础上,构建了一个语义关键词的倒置索引。
在 TF-IDF 模型中,TF(术语频率,Term Frequency)代表术语在数据中出现的频率。我们用
传统的 TF-IDF 计算结果是
此外,我们还借鉴了基于统计方法的语音分类优先权方案 [24],该方案通过使用模糊隐马尔可夫模型来计算语音部分的权重,利用该方法,我们对不同语音部分的关键词的权重定义如下:
那么特征词的权重就是:
链上索引结构:在区块体中建立了一个索引结构(IS)。这个索引结构是由矿工共同维护的,并且在最新的区块中总是最新的。由于它不依赖于任何特定的基础数据库,我们的索引结构与各种区块链系统兼容。
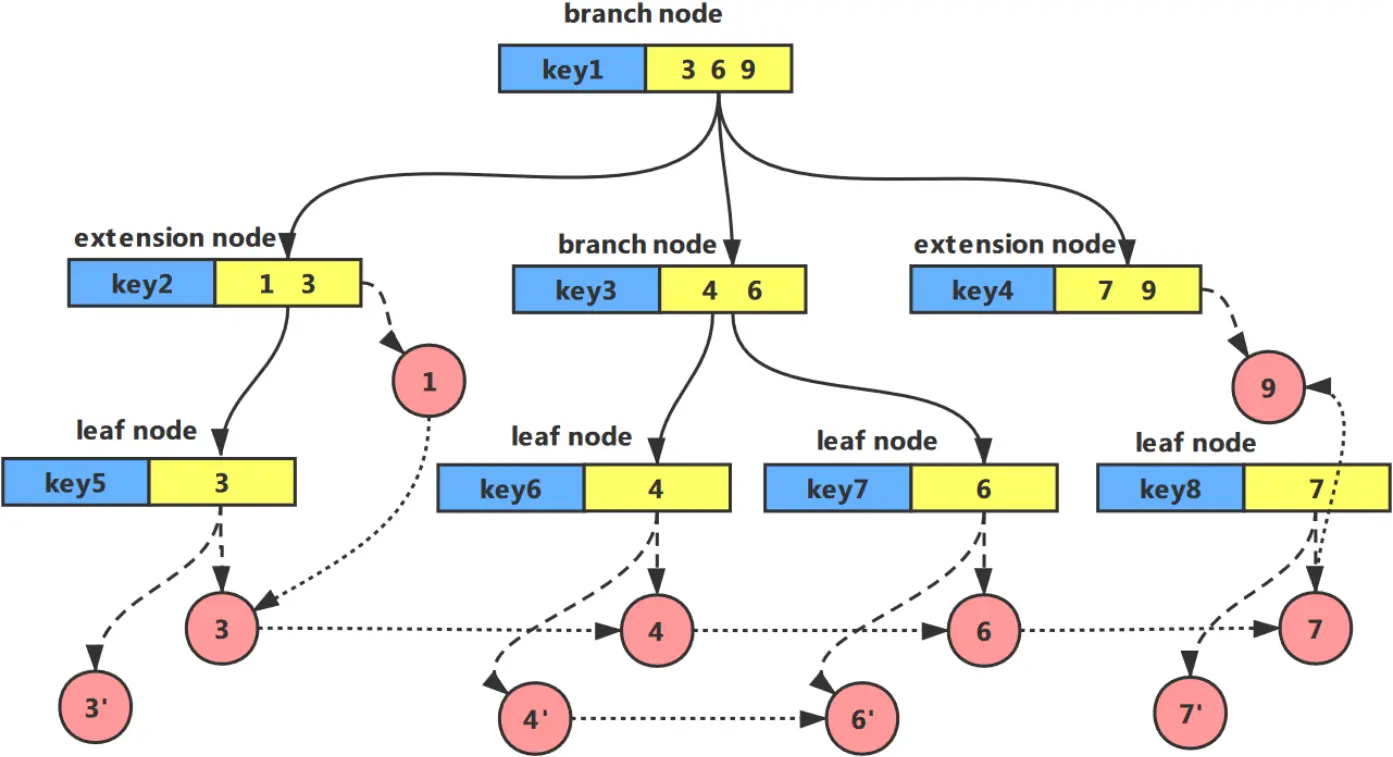
索引结构的生成:在我们的方案中,索引结构是与创世块一起生成的,并随着新块的加入而改变。我们提取链外数据的语义信息,并构建一个关键词的倒置索引。这个倒置的索引允许对单个关键词进行快速的实时查询。为了进一步支持多个关键词的查询,我们构建了一个新的索引结构,称为 Merkle semantic trie(MST),整合了倒置索引、Merkle 树和哈希指针技术。前缀压缩被用来提高多关键词查询的效率。由于区块链的额外性质,MST 是动态构建的,每次产生新的区块时都会更新。
MST 中有三种类型的节点:分支节点、扩展节点和叶子节点。一个节点只能是一种类型。分支节点只存储与索引相关的信息,并提供指向下一级节点的指针;叶子节点位于 MST 的底部,代表搜索路径的终点。查询结果存储在叶子节点中。结果是一个指向相应事务所在块的哈希指针。一个扩展节点不仅包含一个指向下一级的指针,而且还包含查询结果。根节点是特殊的,如果 MST 中只有一个节点,它就充当叶子节点,如果有子节点存在,就充当分支节点。
对于倒置索引中的有序关键词集,矿工将把
算法 1 显示了在 MST 根上的插入处理。为了解释这个算法,我们用一个数据集的例子来模拟一个插入和查询操作。假设要插入的语句是

在 MST 中存储关键词时,借用了 trie 的常见前缀概念。在插入关键词列表时,具有相同前缀的关键词组合的数据会被保存到同一路径。还引入了 Patricia Trie [2] 的思想来压缩只有一个子节点的路径,以充分释放存储空间,MST 的具体结构如图 2 所示。
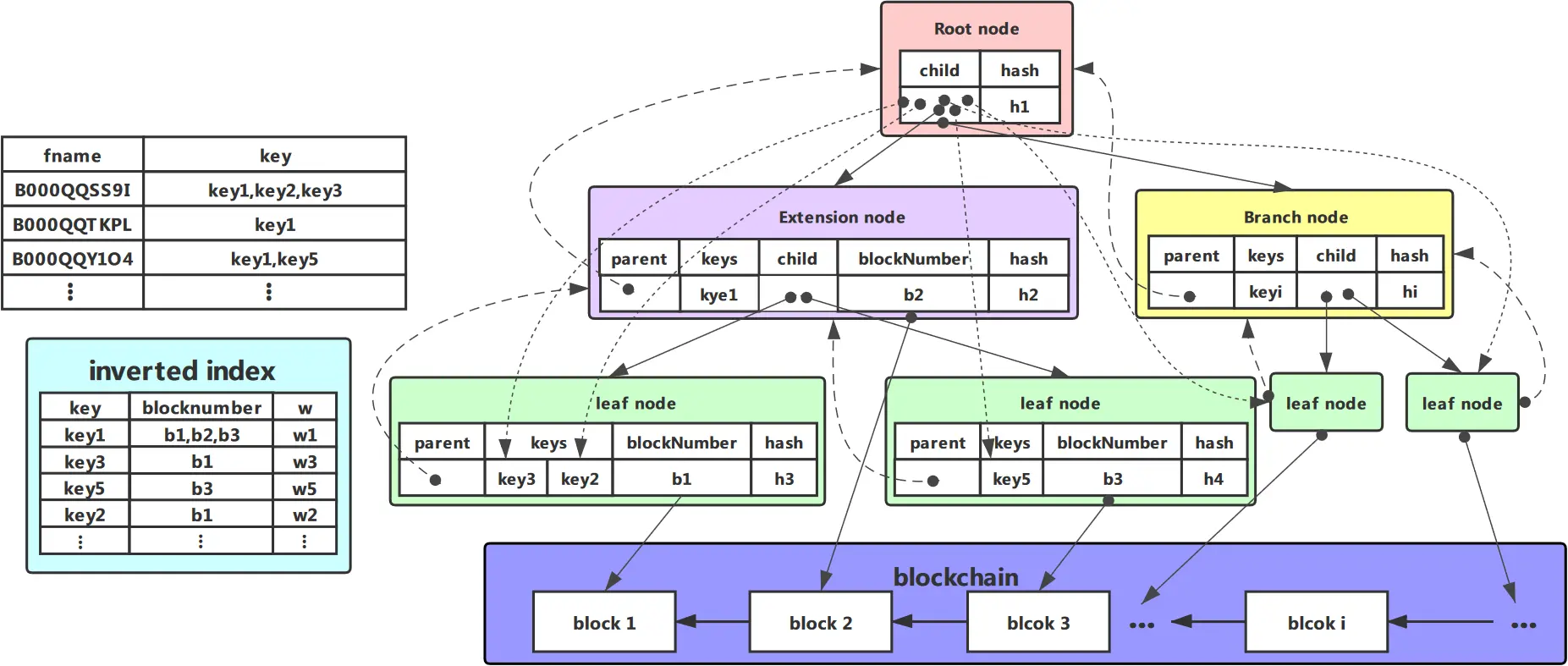
与 merkle 树类似,MST 的每个节点都有一个哈希值。对于一个叶子节点来说,这个哈希值是对存储在叶子节点中的关键词和块指针的哈希运算。
对于一个分支节点,这个哈希值是对关键词及其子节点的哈希值进行的哈希运算:
为了节省存储空间,我们不在块中存储与倒置索引相关的信息,因为 MST 已经包含了所有的关键字信息。一个新加入的节点可以通过使用 MST 在本地恢复倒置索引,也可以连接另一个全节点,同步其倒置索引,然后使用自己的 MST 进行验证。
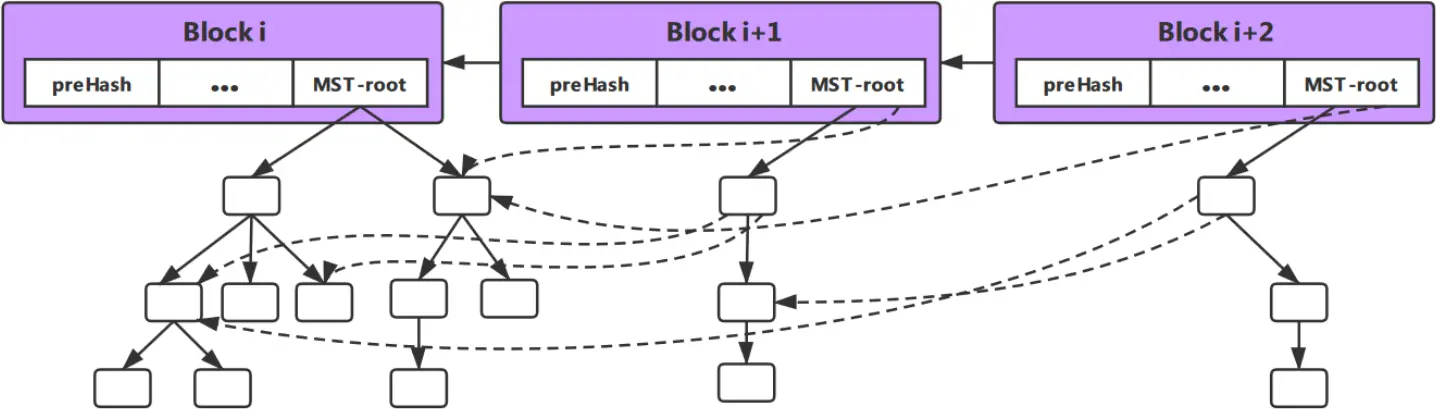
节点的指针:由于 MST 包含了区块链上所有的索引信息,所以随着索引信息的不断添加,索引的大小也会不断增加。但是一个区块中的矿工可能只更新 MST 的一部分,为此我们设计了节点指针结构。如果在一个区块中,MST 的一部分结构没有被更新,就没有必要在区块中保存这一部分。只需要在该部分的子树的父节点上添加一个节点指针。该指针指向该部分的子树中最后一次变化的位置。这种方法有效地减少了区块内的存储成本。一个添加了节点指针的区块链显示在图 3 中。
4.2 查询处理
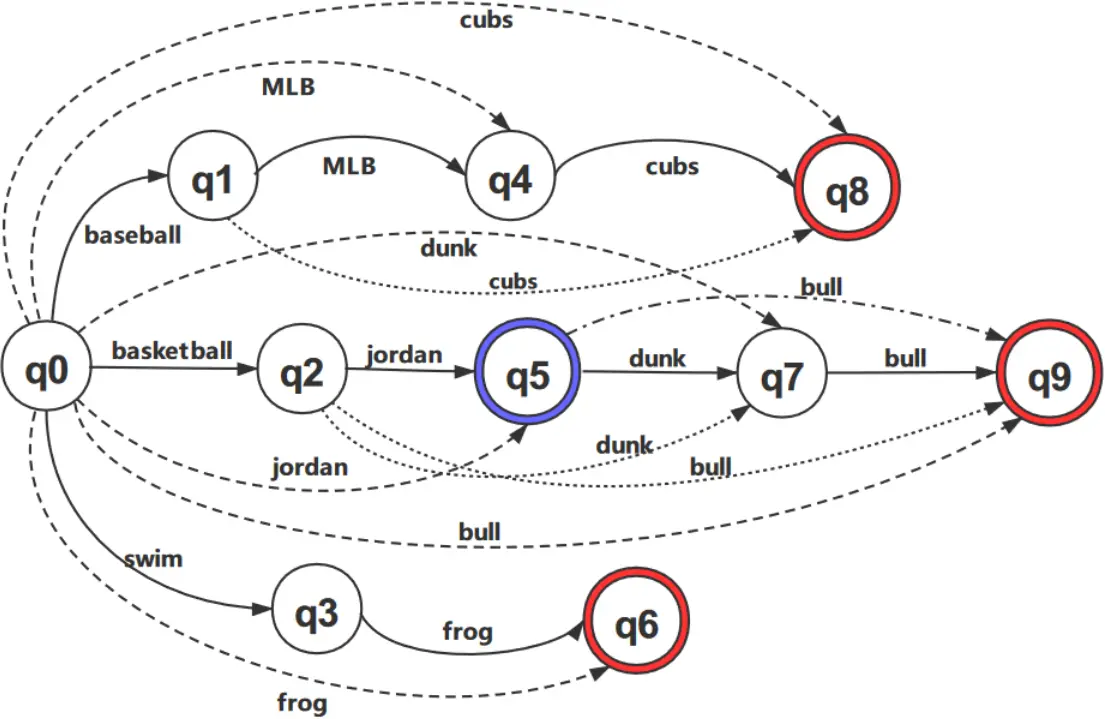
在获得用户的搜索输入后,我们需要将用户输入的关键词组合与 MST 中的索引路径进行匹配,并将匹配结果返回给用户。在匹配过程中,我们使用了与 KMP [25] 类似的多关键词 Aho-Corasick 自动机(MKACA)。但是我们系统中的公共前缀不是一个相同的字符串,而是一组相同的关键词。首先,我们将 MST 映射到 MKACA,如图 4 所示。双层圆圈是接收状态,对应于 MST 中的扩展节点和叶子节点。我们在这里对 MKACA 的改进是,对于一个模糊查询,如果在到达最终状态之前所有的关键词都被匹配,那么到达的状态就变成了模糊的接收状态,此时 MKACA 会返回这个状态之后的所有结果。因为输入关键词的排序已经由倒置索引完成,所以在匹配过程中不会发生递归匹配。在提出多关键词匹配算法之前,我们首先提出以下相关概念:
概念 1:MKACA 是一个五元组
概念 2:对于状态
MKACA 匹配过程如算法 2 所示,通过 MKACA 匹配算法,我们得到了关键词查询结果 R 及其验证对象(

4.3 范围查询支持
通过添加 MST,我们的系统已经支持多关键词查询和模糊查询。然而,由于其底层的 levelDB 数据库在底部使用了 Log Structured-Merge Tree(LSM),因此对范围查询的原生支持并不存在。由于 MST 索引结构需要从根节点到叶节点的查询,我们引入了 B + 树,在不修改底层存储模式的情况下对 MST 节点进行重新排序,这样每个节点都有一个 B + 树范围键值,同时对应一个关键词键值。加入 B + 树后的 MST 如图 5 所示。
与传统的 B + 树不同,我们的 MST-B + 树结构是强关键字 - 数据大小耦合的,不需要在磁盘上进行频繁的 IO 操作。矿工只需要对每个路径上相同关键词所对应的文件范围进行一次排序。
5 实验
在本节中,我们用三个不同的数据集测试了我们的查询方案与其他区块链查询技术的性能对比。
我们的实验是在 64 位 Linux 服务器(Ubuntu 16.04)上使用 Ethereum 的 golang 客户端 geth1.8 进行的,该服务器有 Intel core i7-7700 CPU 和 16GB 的内存。
我们首先测试了索引的时间和存储成本。我们用三个数据集分别测试了四种查询类型在全节点和轻节点上的响应时间。然后,我们比较了加入倒置索引和 MST 之前和之后的查询和检索性能。用不同数量的关键词测试了我们系统的检索性能,同时也测试了 DSE 算法参数对查询相关性的影响。最后,对我们的方案和两个区块链代理查询方案的整体性能进行了比较。
5.1 数据集描述
亚马逊约翰逊音乐标签数据集(AM)
AM 是一个由亚马逊提供的蓝调音乐元信息的公共数据集,包括约 305KB 的元数据和 35MB 的相应音乐信息数据。其元数据使用 json 格式。
Steam 捆绑数据集(SB)
SB 是游戏平台 Steam 上的一个用户线数据集,由用户 ID、游戏标题、捆绑名称和价值组成。我们采用这个数据集进行范围查询测试。
交通数据集(TAXI)
TAXI 是香港大学提供的一个公共数据集,包含罗马、上海、博洛尼亚和科隆四个城市的 4000 辆出租车的 24 小时行驶数据。数据格式为
。
我们系统的数据来源并不限于区块链相关的交易。随着智慧城市的发展,未来的区块链也可能承载来自边缘物联网设备的数据 [26]。因此,我们的实验中考虑到了未来的数据共享需求。
5.2 索引成本
时间成本:与传统的区块链不同,我们的方案中最耗时的部分是索引结构 MST 的生成。时间成本可以用以下方式表示:
在时间间隔 中,索引的时间成本由索引插入操作和索引更新操作所花费的时间组成。索引更新的时间成本包括 MST 更新和倒置索引更新所花费的时间。 存储成本:由于每个区块的交易量可能不同,我们测试了不同交易数据大小下区块所占用的空间。
为了确定添加 MST 指数对区块生成的影响,分别测试了添加指数之前和之后的时间和存储成本。结果显示在图 6 和图 7 中。
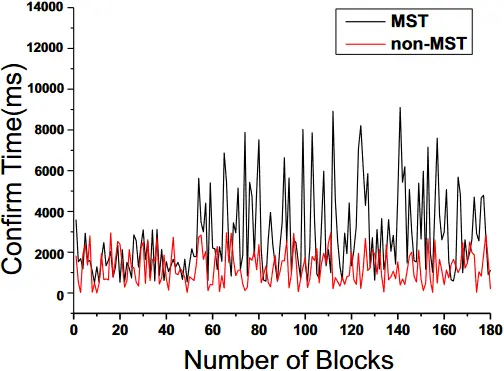
图 6. 使用和不使用 MST 生成块的时间。
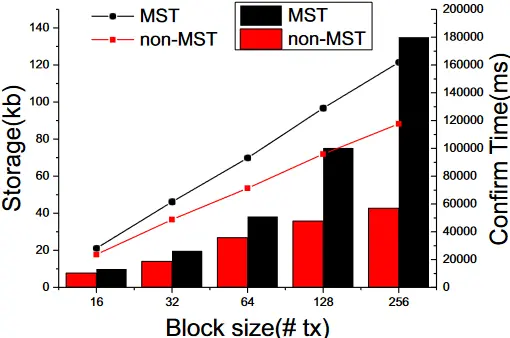
图 7. 使用和不使用 MST 生成块的平均存储成本和时间。
图 6 显示了在不同数量的区块下,生成一个有索引和无索引的区块的时间。结果显示,增加 MST 导致平均区块生成时间增加约 0.5 秒,这是可以接受的。图 7 显示了包含不同数量交易的区块的平均大小。可以看出,由于增加了 MST,非交易密集型区块的存储量有轻微增加。考虑到以太坊目前的吞吐量,增加 MST 不会导致平均区块大小的显著增加。
5.3 查询性能
系统的有效性主要由系统的响应时间、精确性和召回率来检验,它们与我们前面提到的效率、正确性和完整性相对应。
响应时间:在响应时间实验中,我们测试了三种不同数据集(AM、SB、TAXI)下四种查询类型(基本查询、语义关键词查询、模糊查询、范围查询)的平均查询时间和最坏情况的查询时间。基本查询涵盖以太坊的 getBalanceByAddress、getBlockByHash 和 getTransactionByHash。由于轻节点采用代理查询的方式,它需要与网络上的全节点进行通信,并验证查询结果。所以在响应时间实验中,轻节点和全节点是分开测试的。
从表一可以看出,对于四种查询类型,我们方案的平均响应时间都在 20ms 以内。从表二中可以发现,在代理查询的情况下,光节点的查询结果验证时间相当短,这说明我们的代理查询机制的验证效率很好。我们得到了不同查询规模下的三个数据集的累计响应时间,统计结果如图 8 所示。

image-20220523104127812 表一 四种查询类型的响应时间。
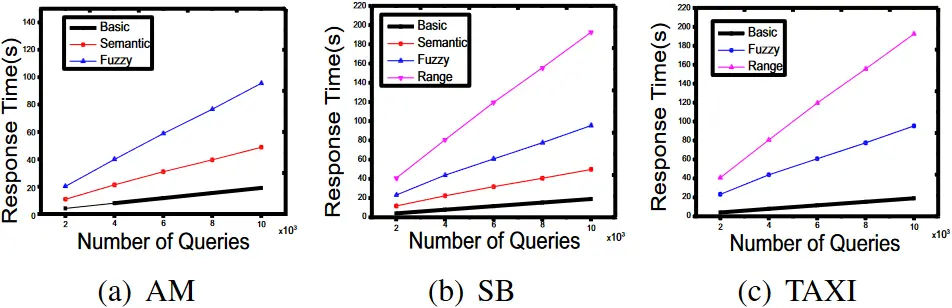
图 8. 三个不同数据集的响应时间。
MST 和倒置索引的性能。为了验证 MST 和倒置索引在我们方案中的重要性,我们通过可变控制方法在 AM 数据集上测试了系统关键词查询性能。分别测试了有 MST 和没有 MST 的关键词查询响应时间。由于以太坊原生不支持关键词查询,我们编写了一个智能合约,通过采取循环扫描的方式测试以太坊在没有 MST 的情况下的关键词查询性能。第二个实验是测试有无倒置索引的不同数量的查询下的累积响应时间。如果没有倒置索引,就需要通过 DSE 算法对从链外数据中提取的关键词进行随机排序,因此插入到 MST 中的关键词组合也需要进行充分的稀释。
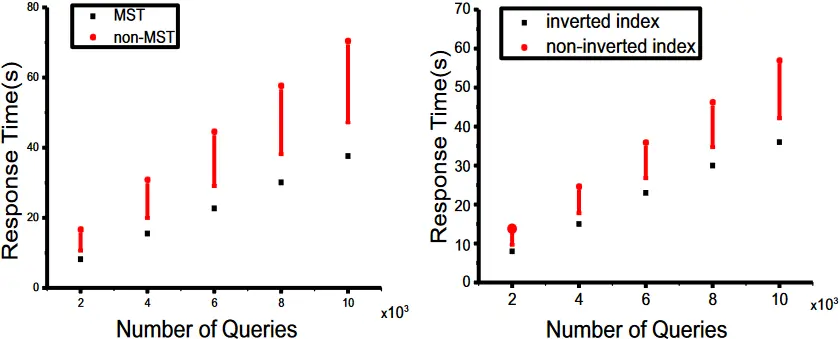
图 9. MST 和倒置指数在响应时间上的表现结果
结果显示在图 9 中。我们可以在第一张图中看到,加入 MST 结构后,与简单的以太坊相比,平均查询时间下降了 50% 以上。第二张图显示,在没有倒置索引的情况下,MST 本身只提供了有限的查询性能改进。因此,为了获得最佳的查询性能,倒置索引和 MST 都需要正常运作。
精度、召回率和排名性能:为了测试我们方案的正确性和完整性,我们用精度来表示正确性,用召回率来表示完整性,另外,我们用平均倒数排名(MRR)来测试 DSE 算法的排名性能。我们首先用 1 到 5 个关键词测试了查询精度和召回率。为了权衡精度和召回率,我们使用二者的谐波平均值,即
值,其计算方法是: 其中 代表精度, 代表召回率, 是 和 的比例。在这里,我们把 设定为 ,因为我们认为精度和召回率同样重要。测试结果见表三。 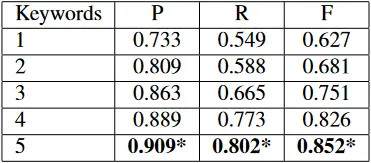
表三:不同关键词数量下的精度、召回率和 F 值
从表三的结果中,我们可以发现,随着关键词数量的增加,精度的提高幅度逐渐变小,而召回率的提高也是先上升后下降。总的来说,随着关键词数量的增加,系统的精度和召回率都有所提高。值得一提的是,表四中的结果显示,从系统中移除倒置的列表会导致精度的下降,尤其是召回率的下降。
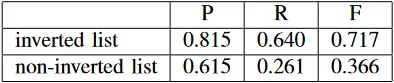
表四:有无倒置指数的精确度、召回率和 F 值
随后,我们使用相关指标 MRR 来测试我们的 DSE 算法在关键词排名上的表现。MRR 代表多个查询的逆向排名的平均值,其定义为:
其中, 代表第 个查询的相关文档的排名。 我们选择了
和 两种情况的 四个不同的值进行 MRR 统计。统计结果见表五。 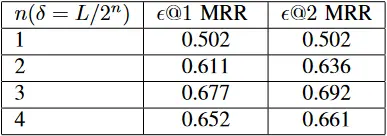
image-20220523105815513 表五:δ 值分别为 1 和 2 时,对 DSE 算法的关键词排名性能的影响。
根据表五,随着
离初始坐标越来越远,DSE 的关键词排名性能先升后降,而在 时达到峰值。 此外,值得注意的是,假阳性是一个不容忽视的问题,基于 MST 的搜索方法中假阳性的概率
的方程式定义如下: 其中 是 MST 的层数, 和 分别是关键词和哈希函数的数量。 总体表现:我们的方案与 vChain [12] 和 SEBDB [27] 的检索性能进行了比较。这三个方案都支持代理查询和非代理查询,并为查询结果提供一个验证对象(
)。我们在实验中重点关注代理查询,在数据集 SB 上进行了 18000 次关键词查询和范围查询。我们测试了不同块数下 占用的存储空间和不同数量的查询结果下 的累计验证时间,然后比较了三种方案的 大小和 验证时间。测试结果如图 10 所示。 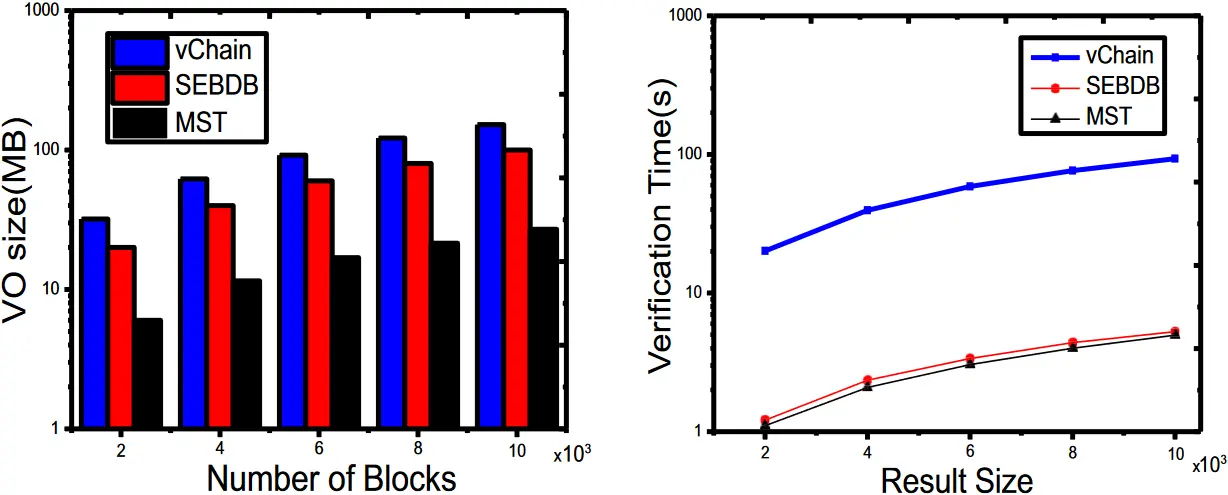
- VO 尺寸 (b) 验证时间
图 10. 我们的 MST 系统与 vChain 和 SEBDB 的整体性能比较
我们方案的
大小约为 的 ,约为 的 。与 相比,我们方案的验证时间明显减少,略低于 的验证时间。可以得出结论,对于关键词查询,我们的方案承诺比 和 的 大小更小,验证时间更短。
6 结论
在本文中,我们首次通过索引实现了链上和链下数据之间的映射,以便在区块链上进行有效查询。我们提出了一种新的语义关键词提取算法,用于从链外数据中提取语义关键词,并根据其重要性进行排序,建立一个倒置的索引。基于这个索引,我们设计了一个名为 Merkle semantic trie(MST)的链上索引结构。MST 提供了关键词查询、范围查询和模糊查询功能,其自身的前缀匹配功能与 MKACA 和 B + 树相结合,并可随时适用于各种类型的区块链基础数据库。提出的方案得到了实现,并对系统性能进行了测试。四种查询类型的响应时间与现有区块链检索方案的比较表明,我们的方案具有更好的查询性能。
在实现了混合存储区块链的高效查询后,我们将转向对数据查询能力和性能的优化。将采用深度学习、卷积神经网络(CNN)和深度信任模型来处理链上和线下数据,进行复杂的数据处理和检索,最终实现全自动的数据分析。
鸣谢
这项工作得到了国家重点研发计划(2018YFE0126000)、国家自然科学基金委员会 -- 通联基金重点项目(U1636209)、国家自然科学基金(61902292)和陕西省重点研发计划(2019ZDLGY13-07 和 2019ZDLGY13-04)的资助。
参考文献
S. Nakamoto, “Bitcoin: A peer-to-peer electronic cash system,” http://bitcoin. org/bitcoin. pdf,” 2008.
G. Wood et al., “Ethereum: A secure decentralised generalised transaction ledger,” Ethereum project yellow paper, vol. 151, no. 2014, pp. 1–32, 2014.
P. Ruan, G. Chen, T. T. A. Dinh, Q. Lin, B. C. Ooi, and M. Zhang, “Finegrained, secure and efficient data provenance on blockchain systems,” Proceedings of the VLDB Endowment, vol. 12, no. 9, pp. 975–988, 2019.
K. Francisco and D. Swanson, “The supply chain has no clothes: Technology adoption of blockchain for supply chain transparency,” Logistics, vol. 2, no. 1, p. 2, 2018.
A. Dell’Anna, “OHLCV, social and blockchain cryptocurrency data analysis and price forecasting,” Ph.D. dissertation, Politecnico di Torino, 2019.
J. Zhou, F. Tang, H. Zhu, N. Nan, and Z. Zhou, “Distributed data vending on blockchain,” in 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData). IEEE, 2018, pp. 11001107.
J. Eberhardt and J. Heiss, “Off-chaining models and approaches to offchain computations,” in Proceedings of the 2nd Workshop on Scalable and Resilient Infrastructures for Distributed Ledgers, 2018, pp. 7–12.
T. McConaghy, R. Marques, A. M ̈ uller, D. De Jonghe, T. McConaghy, G. McMullen, R. Henderson, S. Bellemare, and A. Granzotto, “Bigchaindb: a scalable blockchain database,” white paper, BigChainDB, 2016.
Y. Li, K. Zheng, Y. Yan, Q. Liu, and X. Zhou, “EtherQL: a query layer for blockchain system,” in International Conference on Database Systems for Advanced Applications. Springer, 2017, pp. 556–567.
M. El-Hindi, C. Binnig, A. Arasu, D. Kossmann, and R. Ramamurthy, “BlockchainDB: a shared database on blockchains,” Proceedings of the VLDB Endowment, vol. 12, no. 11, pp. 1597–1609, 2019.
T. T. A. Dinh, J. Wang, G. Chen, R. Liu, B. C. Ooi, and K.-L. Tan, “Blockbench: A framework for analyzing private blockchains,” in Proceedings of the 2017 ACM International Conference on Management of Data, 2017, pp. 1085–1100.
C. Xu, C. Zhang, and J. Xu, “vchain: Enabling verifiable boolean range queries over blockchain databases,” in Proceedings of the 2019 International Conference on Management of Data, 2019, pp. 141–158.
J. H. Paik, “A novel TF-IDF weighting scheme for effective ranking,” in Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, 2013, pp. 343–352.
K. J. O’Dwyer and D. Malone, “Bitcoin mining and its energy footprint,” 2014.
E. Androulaki, A. Barger, V. Bortnikov, C. Cachin, K. Christidis, A. De Caro, D. Enyeart, C. Ferris, G. Laventman, Y. Manevich et al., “Hyperledger fabric: a distributed operating system for permissioned blockchains,” in Proceedings of the Thirteenth EuroSys Conference, 2018, pp. 1–15.
S. J. Arulmozhi, K. Praveenkumar, and G. Vinayagamoorthi, “BITCOIN IN INDIA: A DEEP DOWN SUMMARY,” Advance and Innovative Research, p. 28, 2019.
J. Benet, “Ipfs-content addressed, versioned, p2p file system,” arXiv preprint arXiv:1407.3561, 2014.
H. Bast and B. Buchhold, “An index for efficient semantic full-text search,” in Proceedings of the 22nd ACM international conference on Information & Knowledge Management, 2013, pp. 369–378.
A. Van den Bosch, T. Bogers, and M. De Kunder, “Estimating search engine index size variability: a 9-year longitudinal study,” Scientometrics, vol. 107, no. 2, pp. 839–856, 2016.
G. R. Mitchell and M. E. Houdek, “Hash index table hash generator apparatus,” Jul. 29 1980, uS Patent 4,215,402.
F. Li, M. Hadjieleftheriou, G. Kollios, and L. Reyzin, “Dynamic authenticated index structures for outsourced databases,” in Proceedings of the 2006 ACM SIGMOD international conference on Management of data, 2006, pp. 121–132.
F. Scholer, H. E. Williams, J. Yiannis, and J. Zobel, “Compression of inverted indexes for fast query evaluation,” in Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, 2002, pp. 222–229.
S. Dori and G. M. Landau, “Construction of Aho Corasick automaton in linear time for integer alphabets,” Information Processing Letters, vol. 98, no. 2, pp. 66–72, 2006.
I. N. Yulita, H. L. The, and adiwijaya, “Fuzzy Hidden Markov Models for Indonesian Speech Classification,” Journal of Advanced Computational Intelligence & Intelligent Informatics, vol. 16, no. 3, pp. 381–387.
R. Baeza-Yates and G. H. Gonnet, “A new approach to text searching,” Communications of the ACM, vol. 35, no. 10, pp. 74–82, 1992.
J. Feng, F. R. Yu, Q. Pei, X. Chu, J. Du, and L. Zhu, “Cooperative Computation Offloading and Resource Allocation for Blockchain-Enabled Mobile Edge Computing: A Deep Reinforcement Learning Approach,” IEEE Internet of Things Journal, 2019.
Y. Zhu, Z. Zhang, C. Jin, A. Zhou, and Y. Yan, “SEBDB: Semantics empowered blockchain database,” in 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 2019, pp. 1820–1831.